
前言
笔者这一段时间学习Ozone,翻译和总结一下Ozone的架构,方便读者对ozone有一个深入的了解.
Ozone整体架构
Ozone是一个分布式的,存在多个副本的对象存储系统,对于大数据(元数据)做了优化,目标是10亿级别以上的对象存储
Ozone 对命名空间和block空间做了分离,OM管理命名空间,SCM管理块空间
Ozone 包含 volumes,buckets,keys 一个volumes类似于一个主目录,只有管理员才可以创建
Ozone 由很多的volumes组成,同时volumes也存储账户管理
- Ozone架构图
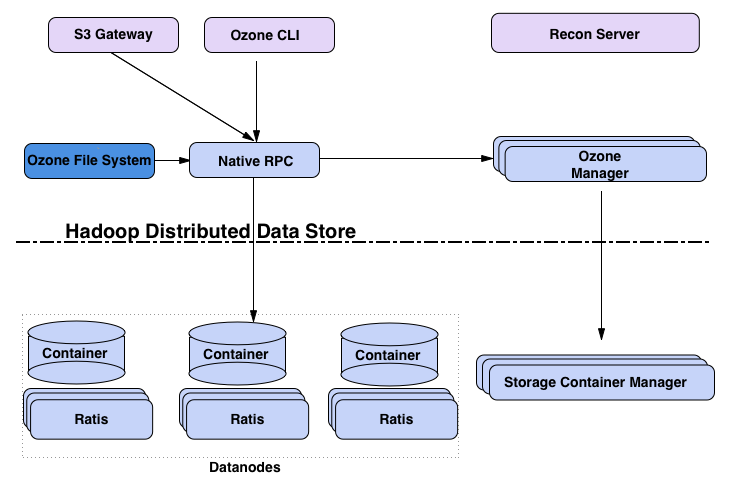
- Ozone Manager 管理命名空间
- Storage Container Manager 管理底层的数据
- Recon 管理Ozone接口
- 多角度查看Ozone
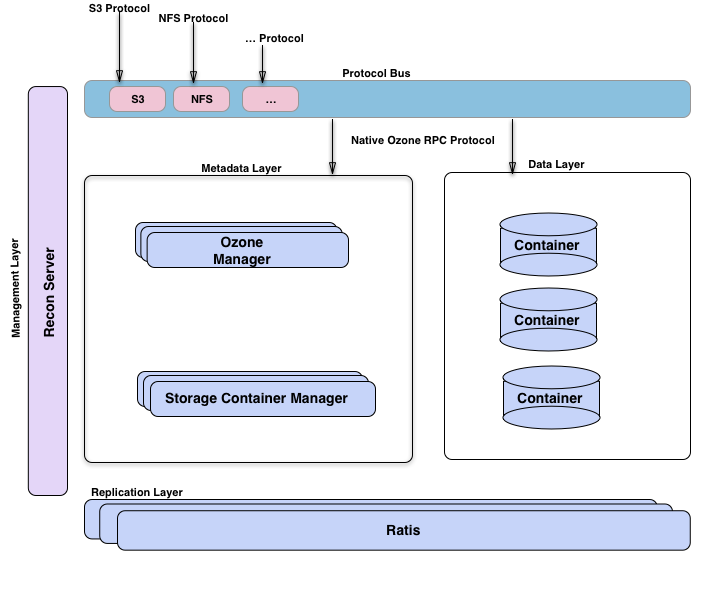
从上图可以看出由 OM 和 SCM 组成的元数据管理层;由数据节点以及 SCM 构成的数据存储层; 由 Ratis 提供的副本层,用来复制 OM 和 SCM 的元数据以及在修改数据节点上数据时保持数据一致性; Recon 是管理服务器,它负责和其它 Ozone 组件通信,并提供统一的管理 API 和界面
Ozone Manager
Ozone Manager(OM)管理 Ozone 的命名空间。 当向 Ozone 写入数据时,你需要向 OM 请求一个块,OM 会返回一个块并记录下相关信息。当你想要读取那个文件时,你也需要先通过 OM 获取那个块的地址。 OM 允许用户在卷和桶下管理键,卷和桶都是命名空间的一部分,也由 OM 管理。 每个卷都是 OM 下的一个独立命名空间的根,这一点和 HDFS 不同,HDFS 提供的是单个根目录的文件系统。 与 HDFS 中单根的树状结构相比,Ozone 的命名空间是卷的集合,或者可以看作是个森林,因此可以非常容易地部署多个 OM 来进行扩展。
写入key
- 为了向 Ozone 中的某个卷下的某个桶的某个键写入数据,用户需要先向 OM 发起写请求,OM 会判断该用户是否有权限写入该键,如果权限许可,OM 分配一个块用于 Ozone 客户端数据写入。
- OM 通过 SCM 请求分配一个块(SCM 是数据节点的管理者),SCM 选择三个数据节点,分配新块并向 OM 返回块标识。
- OM 在自己的元数据中记录下块的信息,然后将块和块 token(带有向该块写数据的授权)返回给用户。
- 用户使用块 token 证明自己有权限向该块写入数据,并向对应的数据节点写入数据。
- 数据写入完成后,用户会更新该块在 OM 中的信息。
读取key
- 用户首先向 OM 请求该键的块列表。
- OM 返回块列表以及对应的块 token。
- 用户连接数据节点,出示块 token,然后读取键数据
Storage Container Manager
Storage container manager 提供了多个要的功能,比如集群的管理者,证书认证,块的管理以及副本的管理.
- 集群管理
- SCM负责创建Ozone集群,当SCM通过
init命令初始化后,SCM就管理整个集群的数据节点
- 块管理
- SCM分配块并将其分配给DataNode,客户端直接读取和写入数据块
- 服务身份管理
- SCM的证书颁发机构负责为群集中的每个服务颁发身份证书。
- 副本管理
- SCM跟踪所有块副本。如果数据节点或磁盘丢失,SCM会检测到它并告诉数据节点复制丢失的块,以确保高可用性
DataNode
DataNode是Ozone的工作节点,所有的数据都存储在数据节点上,客户端会根据块来写入数据,DataNode会把这些数据块 聚合到一个存储容器中,一个存储容器包含了用户从客户端写入的数据流和关于这个数据块的元数据
Storage Containers
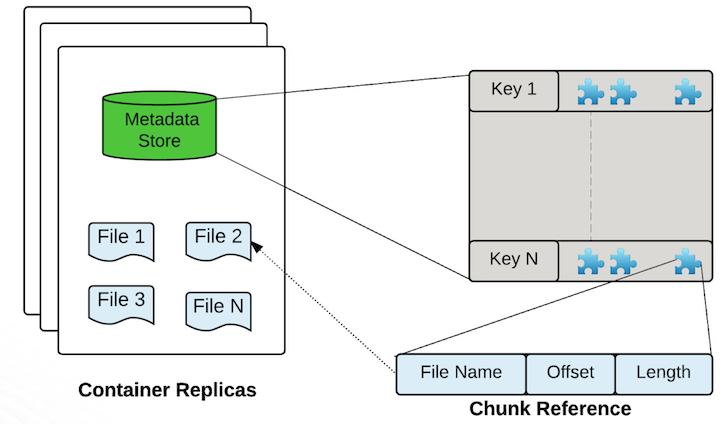
Storage Containers 是一个独立的超级数据块,它包含了一系列的Ozone块以及包含实际数据流的磁盘文件. 这是它的默认存储格式,从Ozone角度来看,容器是一种协议规范,实际上他的存储布局并不重要.换句话说, 扩展或带来新的容器布局很简单,因此它被认为Ozone下容器的参考方案.
理解Ozone数据块和容器
当客户端想要从Ozone读取一个key时,客户端会把键的名称发送给Ozone Manager,Ozone manager 会返回由这个键组成的ozone的数据库列表.
一个Ozone包含了容器ID和一个本地ID,下图显示了Ozone数据块的逻辑布局
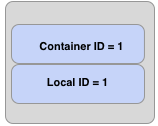
容器ID使得客户端可以发现容器的位置,关于容器的所在的确切的信息存储在容器管理器(SCM), 在大多数情况下,容器的位置被Ozone Manager缓存,并且将于Ozone块一起返回到客户端. 一旦客户端能够找到容器,n那么就知道哪些数据节点包含该容器,客户端将连接到datanode,并且读取 容器ID:本地ID指定的数据流.换句话说,本地ID用作容器的索引,这个容器描述了 我们要从哪里读取数据流.
发现容器的位置
SCM如何知道容器的位置的呢?这与HDFS工作原理非常相似,数据节点定期发送 容器的报告,比如数据块汇报,容器汇报比起块报告更加轻量级,例如,Ozone部署在一个196TB的数据节点 大概有40w个容器,和HDFS百万个半块汇报相比较,块报告将近降低了40倍.
这就额外的间接极大帮助Ozone可以扩展,SCM需要处理的块数据要少得多,而name node是另一种服务, 对于扩展Ozone至关重要。
总结
以上记录了笔者对Ozone概念的总结,后期会更新关于Ozone其他文章.希望对读者起到帮助作用.
参考
- https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/docs/content/concept/Datanodes.md
- http://hadoop.apache.org/ozone/docs/0.5.0-beta/zh/concept/hdds.html




