
前言
笔者早之前就阅读过Netty源代码以及MyBatis源代码,由于早期没有任何经验在阅读源代码是基本上都无从下手,
后来,随着笔者项目和工作经验的增加,对于阅读源代码有了一定的技巧,以Hadoop源代码为例,笔者大致介绍一下
源代码的阅读方法
阅读之前准备
知识储备
举个例子,假如你要阅读Hadoop源代码,首先你要知道很多的分布式系统概念以及计算机网络,比如TCP的相关知识点,对Hadoop原理有一定的深入的理解,并且你已经使用了相当长的时间Hadoop. 笔者不建议你刚刚学习了几天的Hadoop就开始阅读源代码,只要对于你的成长是没有任何意义的.笔者对于知识点的储备罗列一下几点.
- 对Hadoop的概念有深入了解
- 有最少一年的
深度使用和运维经验- 分布式的概念和计算机网络理解深入
- 非常惊人的耐心和毅力
- 一定的数据结构和算法能力
阅读技巧
挑选模块
Hadoop已经发展有十几年代码非常非常庞大,里面的逻辑结构非常非常复杂,Hadoop 目前大致分为HDFS模块,Yarn模块,MapReduce模块以及Tool模块。我们不可能把所有的代码都去阅读,挑选你最感兴趣的.去阅读.如下图为Hadoop源代码trunk分支的代码截图.
最基本入手
由于代码量非常非常庞大,加入你从main方法入口一直去追踪下去,你会发现你最后跟丢了。要从最简单的小的模块看起,比如我们悉知的配置模块已经jmx模块等等,这些模块相对来说是独立的,可以提取出来分析.
跟主线思路
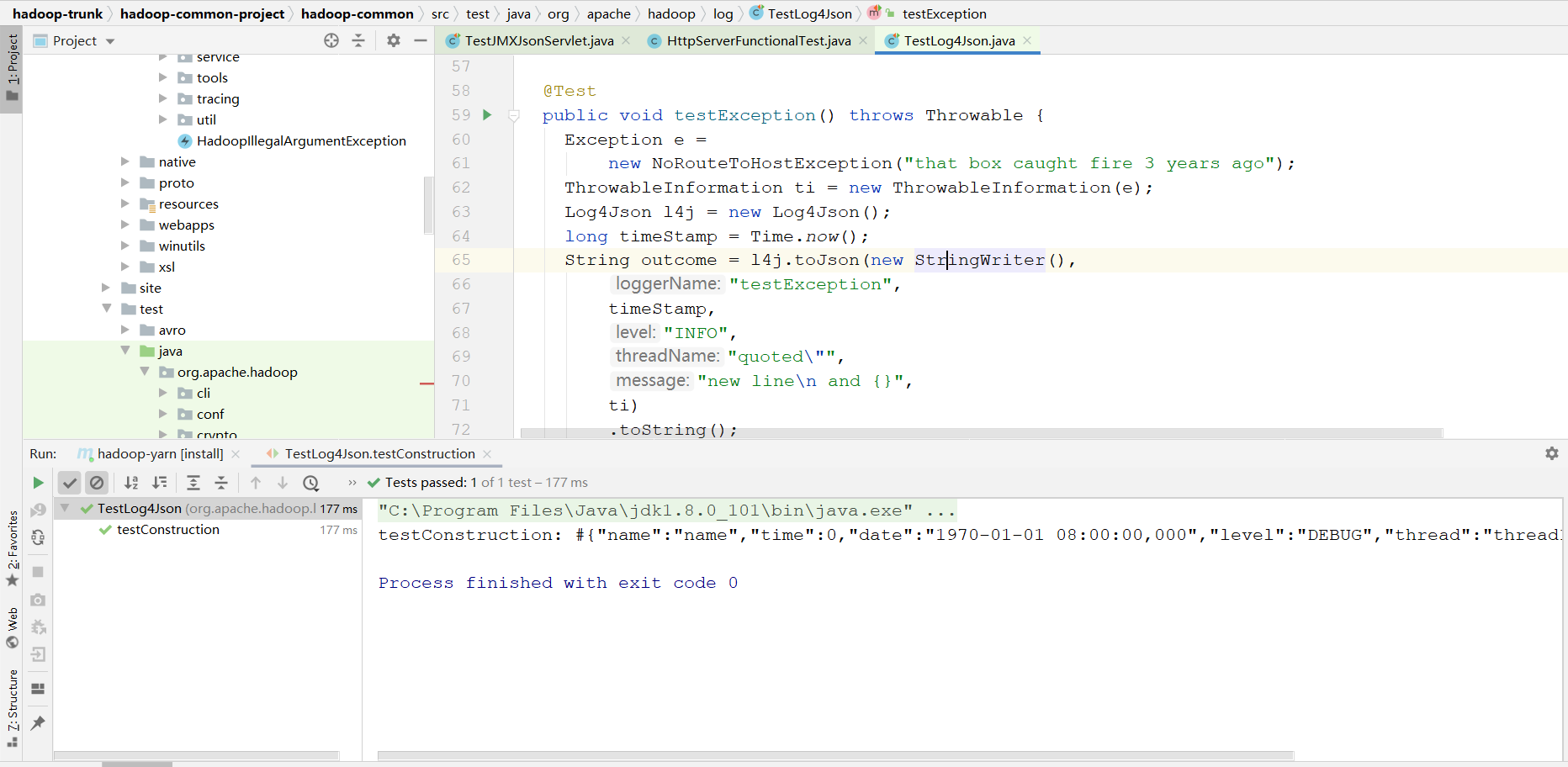
新手阅读源代码的时候往往是看到什么方法就点进去,看到什么类就点进去,如果使用这种方式阅读的话,最后会让你
的耐心被磨光,直到放弃阅读.首先你阅读一个类的时候你要大体知道他是干什么的,然后去找他的测试用例,一般情
况下,看源代码需要一个下手点,大型的框架基本上都是用单元测试的,你从单元测试下手,跟着单元测试走.
debug
在测试用例的代码跟踪进去,然后打断点的方式来调试源代码.
善于使用structure
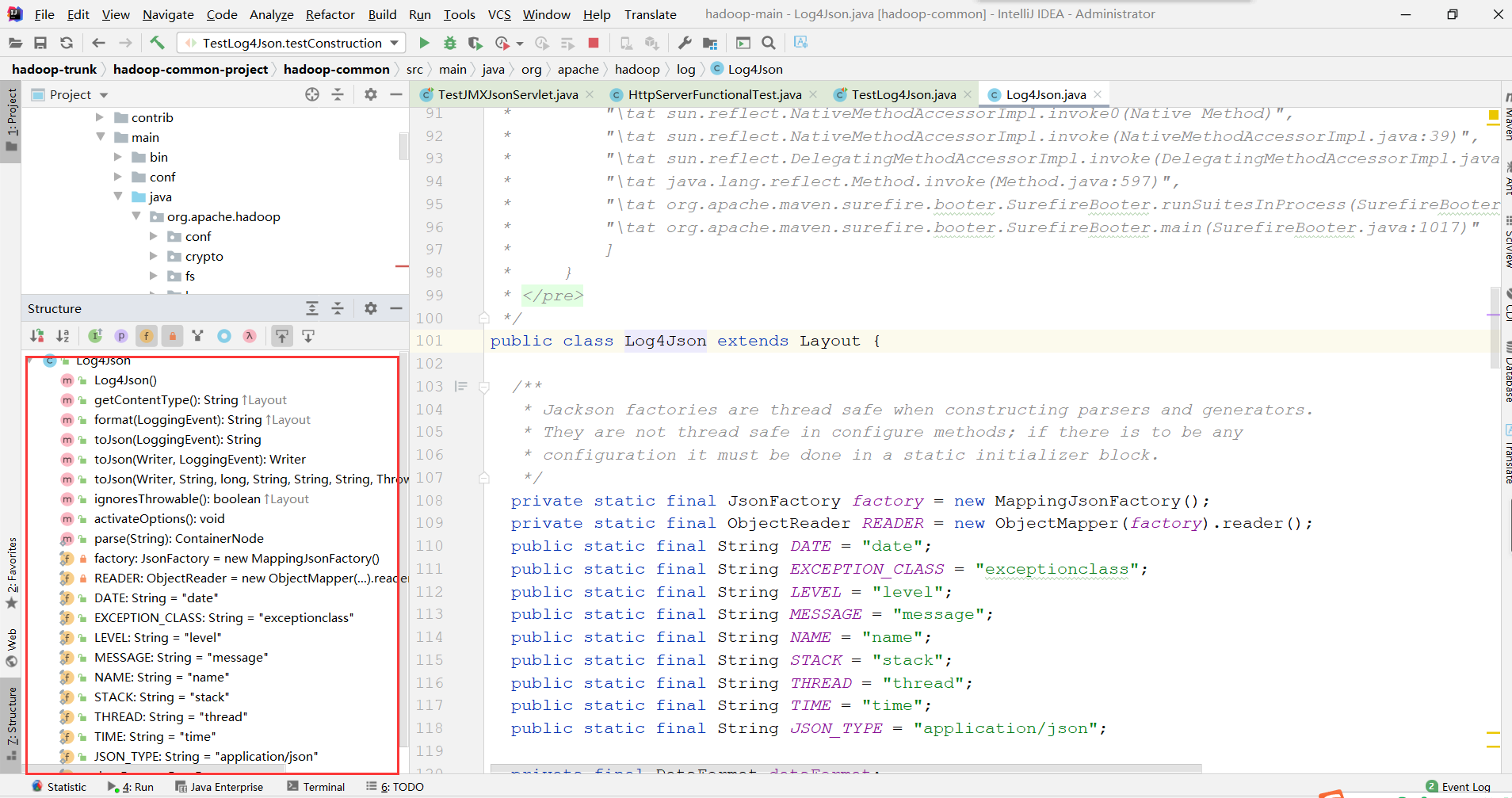
Hadoop代码有的上则几千行,代码结构非常非常庞大,打开structure会让你对大致的方法有一定的了解.
勤于画图总结参考
画图
在阅读的时候需要总结性的画类的结构和状态机图以及时序图.加深对源代码主观上的理解
勤于总结
经常记笔记和写博客是一种不错的记录方法
参考
经常参考别人的总结的,站在巨人的肩膀上,只要走得更远.
总结
以上为笔者大概总结的方法,希望对读者起到一定的帮助.




