
前言
如果读者使用过Hadoop,一定听说过移动计算不移动数据.提到这个就涉及到了Hadoop的机架感知.Hadoop机架感知包括了计算本地化以及
存储分散化.相信很多的大数据使用者都或多或少了解过和配置过Hadoop的机架感知.笔者深入捋一捋Hadoop Common源码结构的部分实现逻辑,
希望本文可以对读者起到一定帮助作用.
核心类
核心类基本介绍
- Node
- InnerNode
- NodeBase
- InnerNodeImpl
- DomainNameResolverFactory
- DFSTopologyNodeImpl
- NetworkTopology
- NetworkTopologyWithNodeGroup
-
Node
在网络拓扑中为底层的接口定义,一个Node节点可能是一个数据节点或者是内部的一个数据中心或者机架.所有的节点的名字和在网络中的位置会按照一定的简单的语法规则写到一个文件中.比如:如果一个数据节点的名字是 主机名:端口 并且他所在的机架是 orange,所在的数据中心是dog 那么使用字符串表示就是/dog/orange
-
InnerNode
继承自Node接口,拓展了Node接口
-
NodeBase
实现了Node基类,增加相关获取树节点的高度和每一行被/分割的字符串解析工作.
-
InnerNodeImpl
继承NodeBase 实现了InnnerNode接口,代表了交换机或者是路由器,和叶子结点不同,他的叶子结点都是非空的.
protected final List<Node> children = new ArrayList<>(); protected final Map<String, Node> childrenMap = new HashMap<>(); -
DomainNameResolverFactory
解析Namenode/Router/RM nameservice/yarnservice名称为真实的IP地址
-
DFSTopologyNodeImpl
继承自InnerNodeImpl该类中涵盖了核心的解析机架配置映射为树结构的逻辑
-
NetworkTopology
比较高层的网络拓扑实现方式,默认的/default-rack
-
NetworkTopologyWithNodeGroup
包含Node组的网络拓扑
类继承关系图[构建树类]
解析给定的数据结构使其成为树结构用来支撑Yarn机架感知和HDFS存储机架感知,核心添加节点和删除节点查询节点的在NetworkTopology
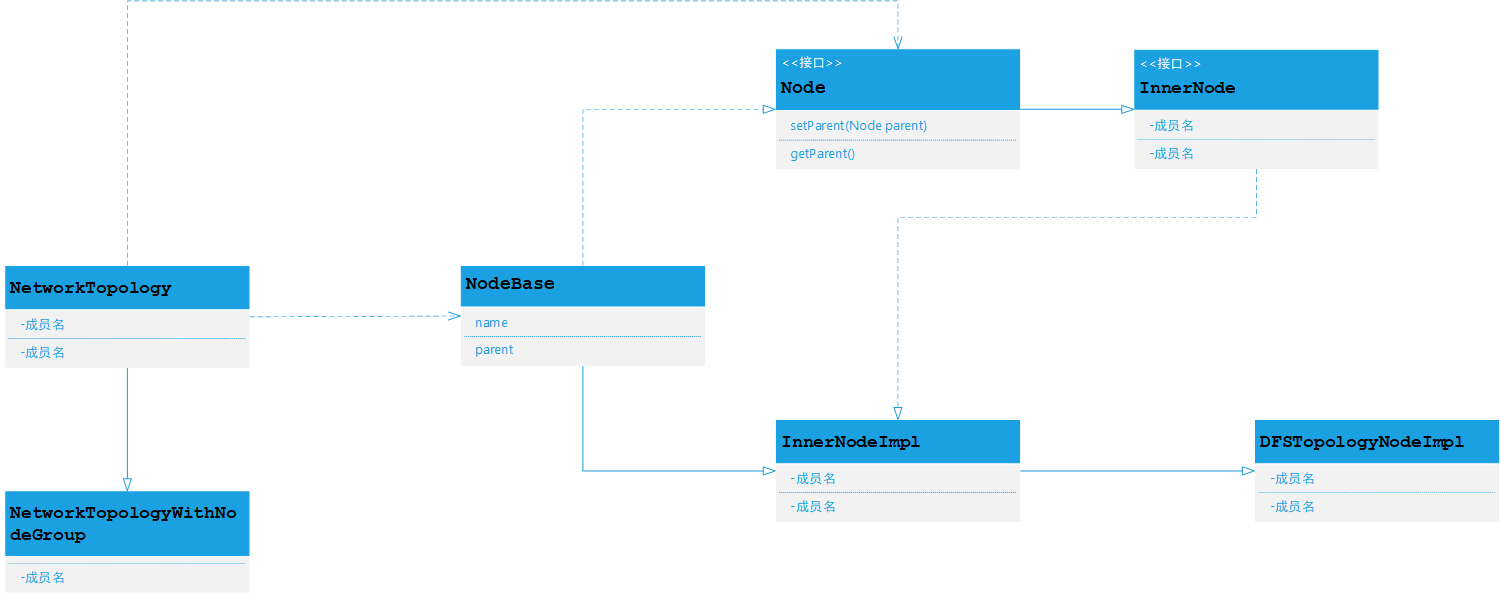
核心类详细解析
NetworkTopology部分解析
- clusterMap 根节点
- depthOfAllLeaves 所有叶子结点的深度
- numOfRacks 所有机架数
- clusterEverBeenMultiRack 该集群是否有多个机架
添加节点方法
public void add(Node node) {
if (node==null) return;
//获取新加节点的深度
int newDepth = NodeBase.locationToDepth(node.getNetworkLocation()) + 1;
//写锁
netlock.writeLock().lock();
try {
if( node instanceof InnerNode ) {
throw new IllegalArgumentException(
"Not allow to add an inner node: "+NodeBase.getPath(node));
}
//判断是有的节点是不是都没有开启机架感知并且所有叶子节点的深度不等于新加的节点的深度
//也就是说整个集群中不允许出现既有开启机架感知的节点又有没有开启机架感知的节点,所以的机架加交换机的深度必须一致
if ((depthOfAllLeaves != -1) && (depthOfAllLeaves != newDepth)) {
LOG.error("Error: can't add leaf node {} at depth {} to topology:{}\n",
NodeBase.getPath(node), newDepth, this);
throw new InvalidTopologyException("Failed to add " + NodeBase.getPath(node) +
": You cannot have a rack and a non-rack node at the same " +
"level of the network topology.");
}
//获取这个节点的机架
Node rack = getNodeForNetworkLocation(node);
if (rack != null && !(rack instanceof InnerNode)) {
throw new IllegalArgumentException("Unexpected data node "
+ node.toString()
+ " at an illegal network location");
}
if (clusterMap.add(node)) {
LOG.info("Adding a new node: "+NodeBase.getPath(node));
if (rack == null) {
incrementRacks();
}
if (depthOfAllLeaves == -1) {
depthOfAllLeaves = node.getLevel();
}
}
LOG.debug("NetworkTopology became:\n{}", this);
} finally {
netlock.writeLock().unlock();
}
}
我们继续看这个方法NodeBase.locationToDepth
public static int locationToDepth(String location) {
String normalizedLocation = normalize(location);
int length = normalizedLocation.length();
int depth = 0;
for (int i = 0; i < length; i++) {
//获取你给出的 字符串normalizedLocation 然后获取字符串中/出现的次数然后重新给定深度
if (normalizedLocation.charAt(i) == PATH_SEPARATOR) {
//统一深度
depth++;
}
}
return depth;
}
继续观察normalize(location);这个方法对比我给出的机架感知的配置
cat topology.data
10.10.21.33 cnbjsjqp-bdp-dn-24 /J/03/
10.10.21.34 cnbjsjqp-bdp-dn-25 /J/03/
10.10.21.35 cnbjsjqp-bdp-dn-26 /SW2/08/
10.10.21.36 cnbjsjqp-bdp-dn-27 /SW2/08/
10.10.21.37 cnbjsjqp-bdp-dn-28 /SW2/08/
public static String normalize(String path) {
if (path == null) {
throw new IllegalArgumentException(
"Network Location is null ");
}
//如果路径的长度为0那么就是ROOT节点也就是没有开启机架感知
if (path.length() == 0) {
return ROOT;
}
//如果不是以/开头直接抛出异常为网络路径必须以/开头
if (path.charAt(0) != PATH_SEPARATOR) {
throw new IllegalArgumentException(
"Network Location path does not start with "
+PATH_SEPARATOR_STR+ ": "+path);
}
//如果字符串的结尾有/ 去掉/ 譬如 /J/03/ 返回 /J/03
int len = path.length();
if (path.charAt(len-1) == PATH_SEPARATOR) {
return path.substring(0, len-1);
}
return path;
}
继续查看核心的clusterMap.add(node)方法,该方法是往树中添加节点
public boolean add(Node n) {
//判断此节点是已经有的机架+交换机的节点并不是当前的网络位置的后代
if (!isAncestor(n)) {
throw new IllegalArgumentException(n.getName()
+ ", which is located at " + n.getNetworkLocation()
+ ", is not a descendant of " + getPath(this));
}
//判断n的父节点是不是当前节点,如果是直接和n关联
if (isParent(n)) {
// 如果是直接和n关联
n.setParent(this);
n.setLevel(this.level+1);
//放到结点的Map Map结构为<Node名字,节点对象>
Node prev = childrenMap.put(n.getName(), n);
if (prev != null) {
for(int i=0; i<children.size(); i++) {
//遍历chidren链表 如果该链表中含有和该节点的名字一样的则替换
if (children.get(i).getName().equals(n.getName())) {
children.set(i, n);
return false;
}
}
}
//把n添加到chidren链表
children.add(n);
numOfLeaves++;
return true;
} else {
//如果n的父节点是不是当前节点则查找下一个父节点名字
String parentName = getNextAncestorName(n);
InnerNode parentNode = (InnerNode)childrenMap.get(parentName);
if (parentNode == null) {
// 如果找不到就重新创建一个父节点
parentNode = createParentNode(parentName);
//把父节点添加到children list中
children.add(parentNode);
///放到父节点的Map中 Map结构为<Node名称,节点>
childrenMap.put(parentNode.getName(), parentNode);
}
// 递归 将n添加到下一个祖先节点的子树中
if (parentNode.add(n)) {
numOfLeaves++;
return true;
} else {
return false;
}
}
}
网络节点的结构图
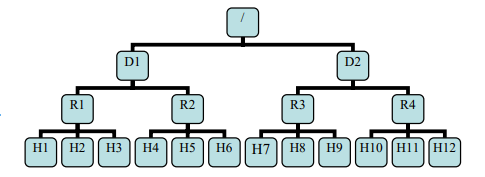
注意上面代码中添加节点的过程中使用到了几个核心的数据结构一个是List
添加过程:
- 判断/D1/R1/H1的父节点是否是R1如果是的话,直接添加到尾部同时添加到Map<String,Node> childrenMap
- 循环遍历List
之前保存的所以的节点的信息 如果名称相同添加不成功。否则添加到List ,叶子节点+1, - 如果这个节点的的父节点不是Node节点,那么寻找他的上一个父节点,如果上一级的父节点也是空那么就创建父节点,最后把n添加到父节点的父节点上
计算两节点之间距离
public int getDistance(Node node1, Node node2) {
if ((node1 != null && node1.equals(node2)) ||
(node1 == null && node2 == null)) {
return 0;
}
if (node1 == null || node2 == null) {
LOG.warn("One of the nodes is a null pointer");
return Integer.MAX_VALUE;
}
Node n1=node1, n2=node2;
int dis = 0;
netlock.readLock().lock();
try {
int level1=node1.getLevel(), level2=node2.getLevel();
while(n1!=null && level1>level2) {
n1 = n1.getParent();
level1--;
dis++;
}
while(n2!=null && level2>level1) {
n2 = n2.getParent();
level2--;
dis++;
}
//查找公共祖先
while(n1!=null && n2!=null && n1.getParent()!=n2.getParent()) {
n1=n1.getParent();
n2=n2.getParent();
dis+=2;
}
} finally {
netlock.readLock().unlock();
}
if (n1==null) {
LOG.warn("The cluster does not contain node: "+NodeBase.getPath(node1));
return Integer.MAX_VALUE;
}
if (n2==null) {
LOG.warn("The cluster does not contain node: "+NodeBase.getPath(node2));
return Integer.MAX_VALUE;
}
return dis+2;
}
下图为例:
S1,S2为交换机,R1,R2,R3为机架.
以N1和N2为例只有最后的return满足即为0+2 距离为2.
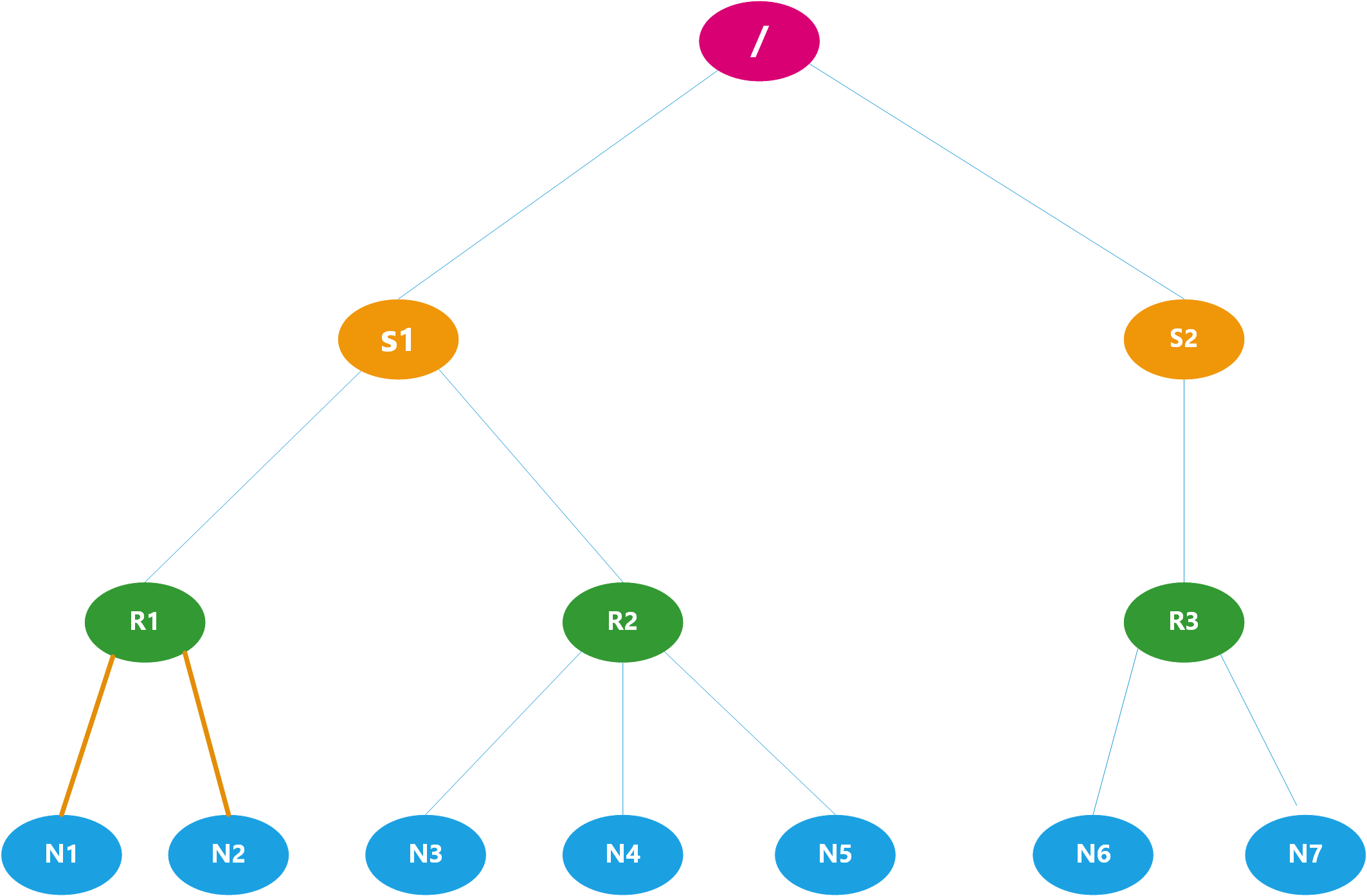
以N1和N7为例,从图中可以看出为6的记录
以为为处理逻辑:
- 两个节点都不是空并且两个节点的高度都是相同,进入上述代码的第3个while循环,寻找两个节点的共同的祖先,第一次循环找到各自的祖先为R1和R3但是他们不相等dist=0+2,此时的dist=2
while(n1!=null && n2!=null && n1.getParent()!=n2.getParent()) {
n1=n1.getParent();
n2=n2.getParent();
dis+=2;
}
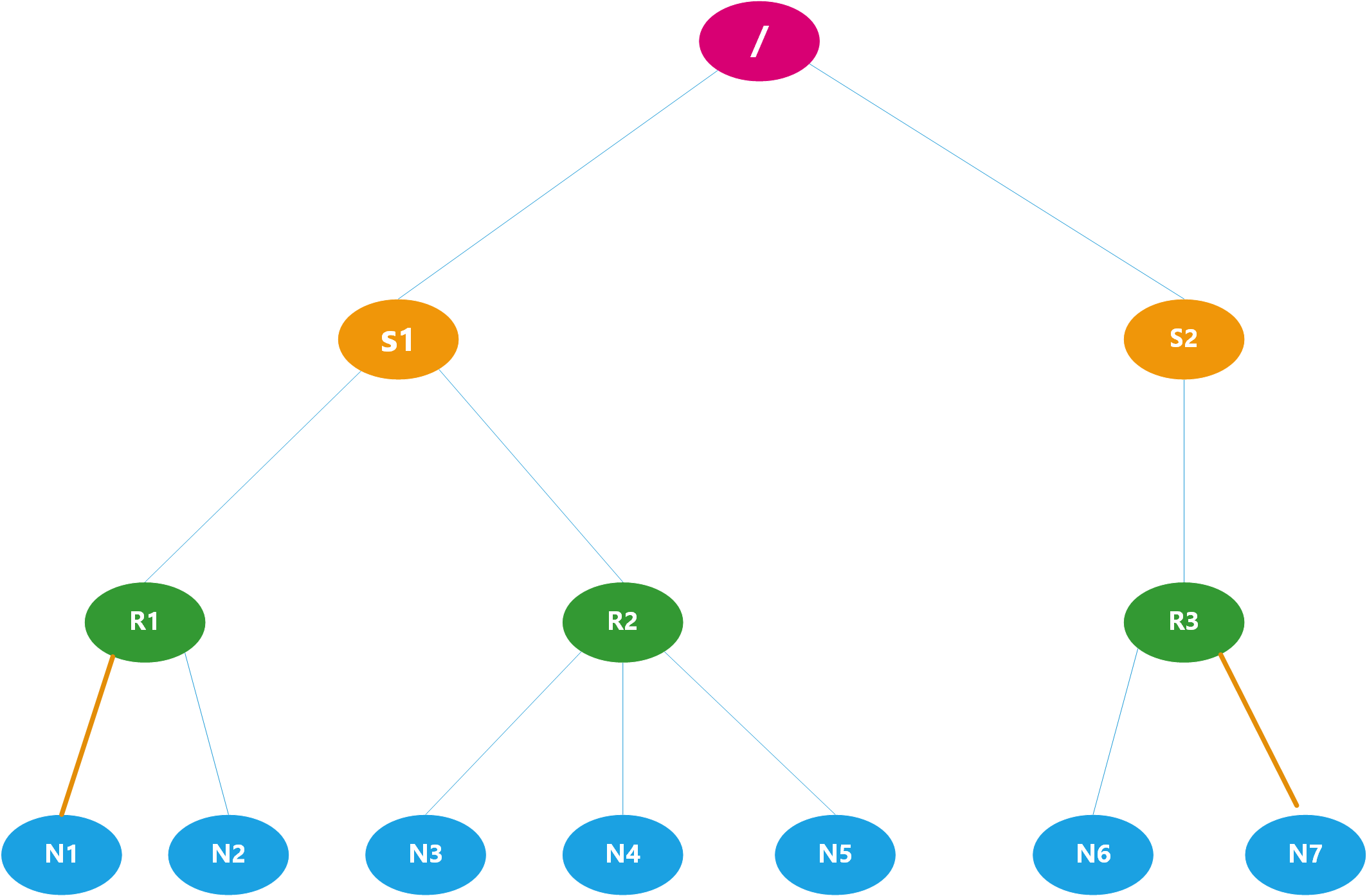
- 继续执行第三个while循环,这是R1和R2父节点都是/ 这是他们的父节点相同退出循环,这是dist=2+2=4
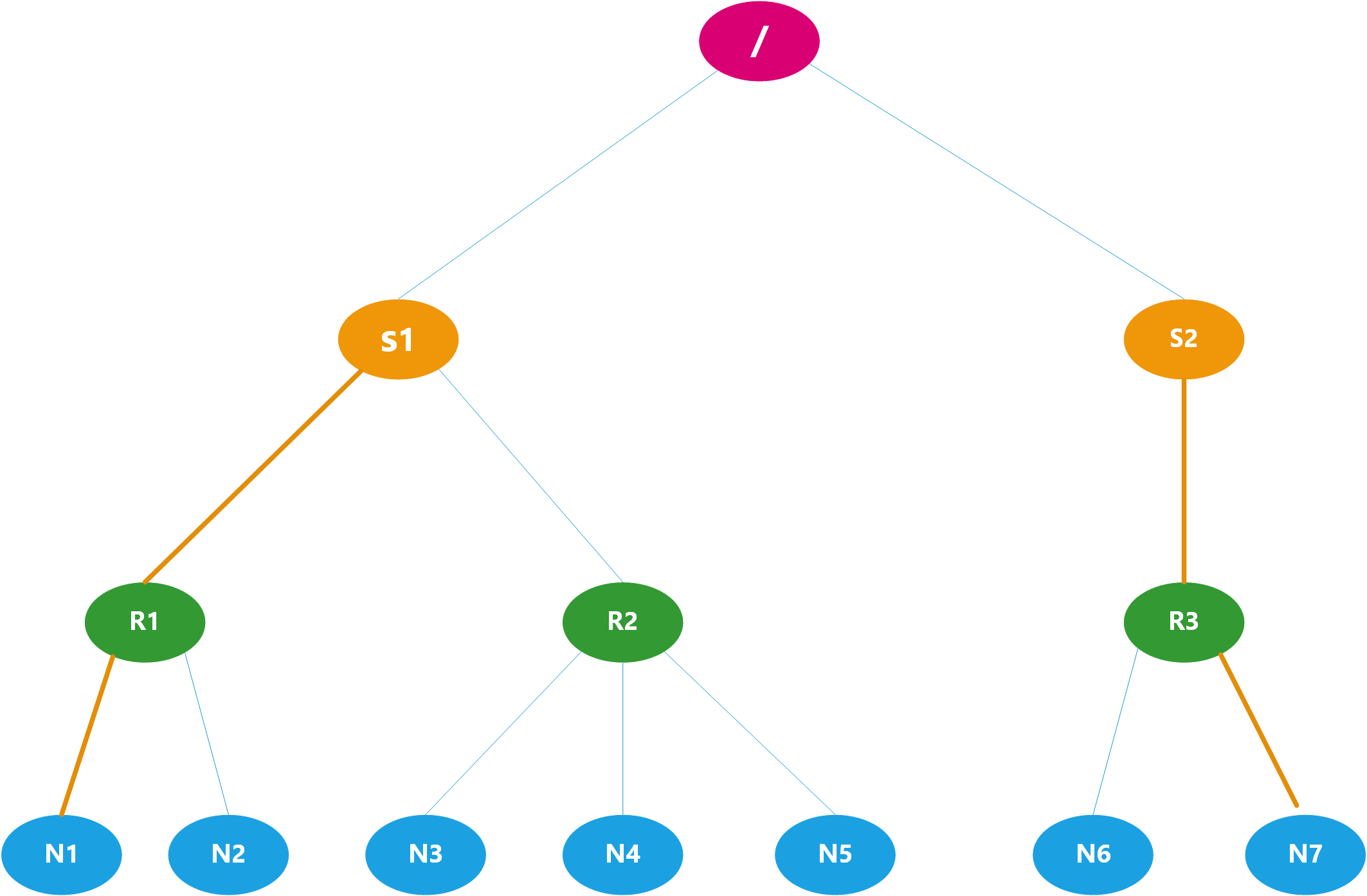
- 执行最后的返回语句dist最终等于 4+2=6,即为如下的图的举例,此时计算出了两个节点的距离
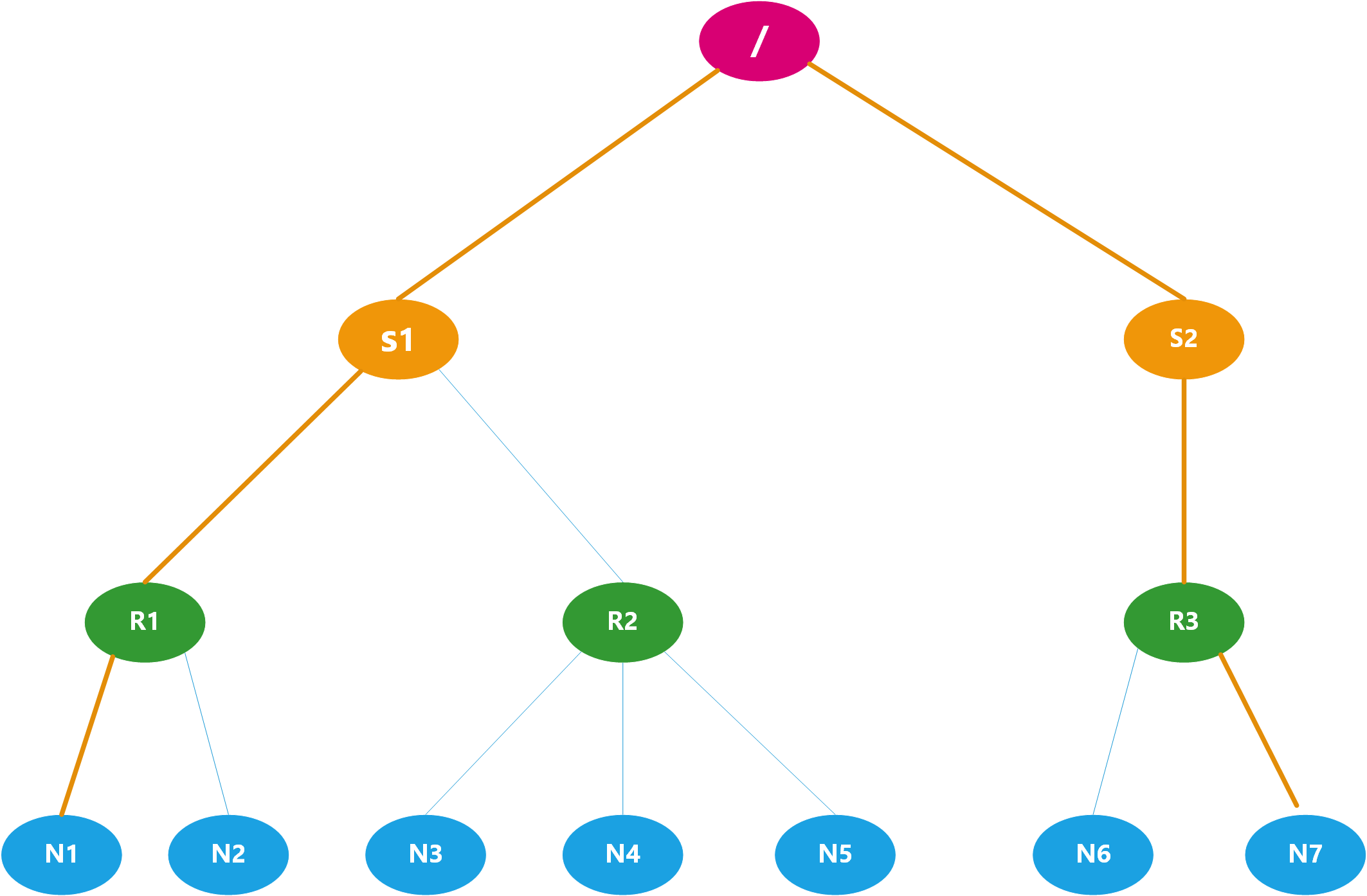
NetworkTopologyWithNodeGroup类
该类扩展了NetworkTopology以表示具有以下内容的计算机集群4层分层网络拓扑。在此网络拓扑中,叶子代表数据节点(计算机)和内部节点代表管理进出数据中心流量的交换机/路由器,机架或物理主机(带有虚拟交换机)
有如下核心方法
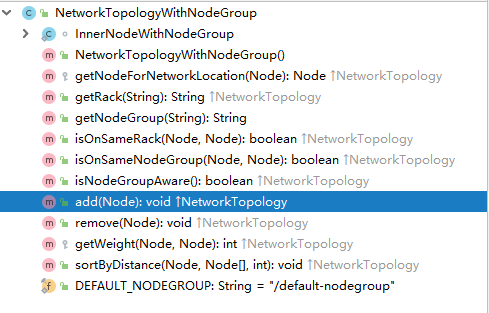
我们平时所说的是否在同一个机架,这里重点看一下该方法:背后的原理是判断node1和node2节点的父节点是相同,如果相同那么就是在同一个机架上
@Override
public boolean isOnSameRack( Node node1, Node node2) {
if (node1 == null || node2 == null ||
node1.getParent() == null || node2.getParent() == null) {
return false;
}
netlock.readLock().lock();
try {
return isSameParents(node1.getParent(), node2.getParent());
} finally {
netlock.readLock().unlock();
}
}
protected boolean isSameParents(Node node1, Node node2) {
return node1.getParent()==node2.getParent();
}
解析机架配置&同时解析主机名类结构图
topology.data topology.sh
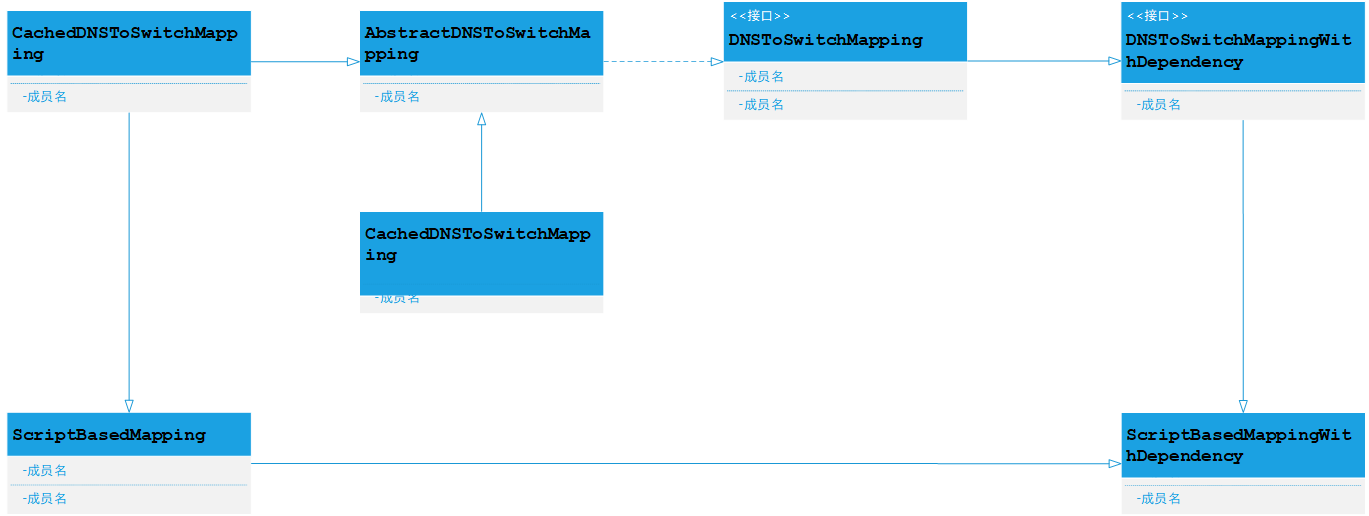
对于如何解析配置该机架感知配置文件和自定义类实现机器节点的位置规划笔者不展开详细的描述,如果感兴趣的话,更多资料请下载Hadoop源代码分析.
总结
以上为笔者总结网络拓扑部分原理,感兴趣的读者可以继续深入学习,希望本文对读者起到一定的帮助.
参考
- https://blog.csdn.net/zqhxuyuan/article/details/10221355
- http://hadoop.apache.org/




