
前言
文件压缩和解压在我们平时使用计算机的时候经常会提到,压缩一定程度上减少了磁盘成本,但是增加了CPU计算成本,在大数据中经常会使用到压缩,
在Hadoop中,我们会经常听说Gzip压缩,Lzo压缩,Snappy压缩,Bzip压缩等等,这些压缩算法各有各的好处.如果压缩速度上快了,自然压缩率会降低一些.笔者
本文聊一聊压缩在Hadoop中的使用和源代码的部分剖析.
压缩算法对比
如下图为压缩算法压缩比和压缩解压速度对比
| 算法 | 压缩比 | 压缩速度 | 解压速度 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
开启自定义压缩算法
-
允许Hadoop支持Lzo压缩
- 添加lzo jar包到 Hadoop的classpath路径下
cp hadoop-lzo-0.4.21-SNAPSHOT.jar /opt/hadoop/share/hadoop/
- 修改core-site.xml文件添加如下配置 ```
io.compression.codecs com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec 3. 修改mapred-site.xmlmapreduce.map.output.compress.codec com.hadoop.compression.lzo.LzoCodec ```
-
检验是否安装正常
在Hive中使用如下命令创建表,若不报错创建成功,并且使用Hive外部表后如果出现
*.lzo*.index文件即为安装成功.CREATE EXTERNAL TABLE test ( columnA string, columnB string ) PARTITIONED BY (date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" STORED AS INPUTFORMAT "com.hadoop.mapred.DeprecatedLzoTextInputFormat" OUTPUTFORMAT "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat" LOCATION '/orgs/test';
压缩在Hadoop源码中的结构
如下图为整体Hadoop压缩和解压的源代码结构
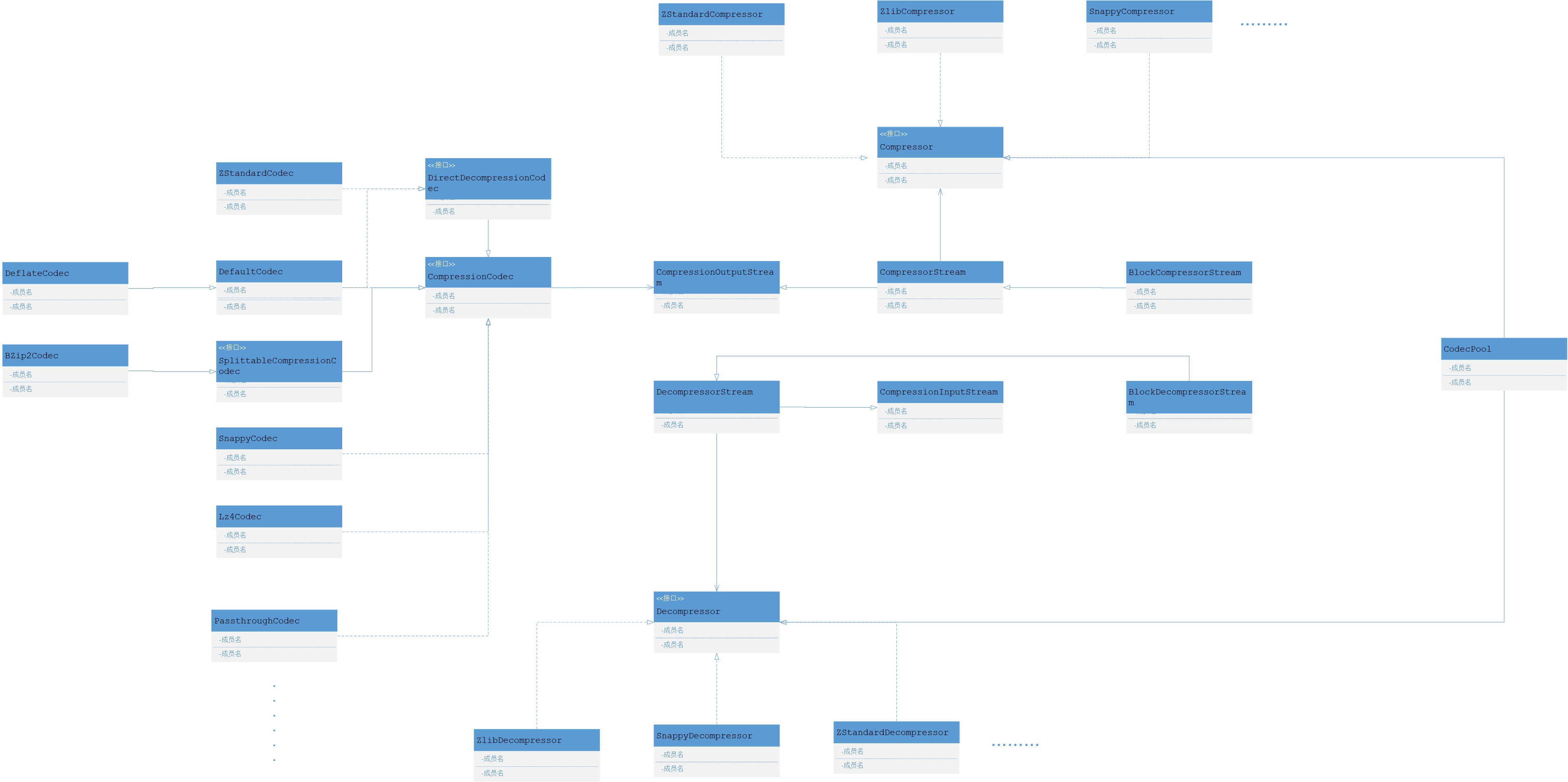
- CompressionCodec 如果你要实现自己的压缩编码请实现该接口
- SplittableCompressionCodec 如果你的算法支持切分压缩你可以继承该类
- Decompressor/Compressor 如果你要实现你的编码解码器请实现这两个方法
核心类详细解析
SnappyCodec部分解析
- createCompressor
- createInputStream
- getDecompressorType
- createCompressor
public Compressor createCompressor() {
checkNativeCodeLoaded();
int bufferSize = conf.getInt(
CommonConfigurationKeys.IO_COMPRESSION_CODEC_SNAPPY_BUFFERSIZE_KEY,
CommonConfigurationKeys.IO_COMPRESSION_CODEC_SNAPPY_BUFFERSIZE_DEFAULT);
return new SnappyCompressor(bufferSize);
}
看出上述方法调用SnappyCompressor的构造方法使用给定的缓存大小,构造方法中采用了分配直接内存的方式,如下为SnappyCompressor
构造方法,使用JDK的直接内存分配方法分配内存.position初始化直接内存的BufferSize.
public SnappyCompressor(int directBufferSize) {
this.directBufferSize = directBufferSize;
uncompressedDirectBuf = ByteBuffer.allocateDirect(directBufferSize);
compressedDirectBuf = ByteBuffer.allocateDirect(directBufferSize);
compressedDirectBuf.position(directBufferSize);
}
- createInputStream
@Override
public CompressionInputStream createInputStream(InputStream in,
Decompressor decompressor)
throws IOException {
checkNativeCodeLoaded();
//创建基于块的解压缩流
return new BlockDecompressorStream(in, decompressor, conf.getInt(
CommonConfigurationKeys.IO_COMPRESSION_CODEC_SNAPPY_BUFFERSIZE_KEY,
CommonConfigurationKeys.IO_COMPRESSION_CODEC_SNAPPY_BUFFERSIZE_DEFAULT));
}
-
getDecompressorType
获取编码的字节码,在获取之前要检查本地的native库是否已经被加载,如果没有被加载直接报错
@Override public Class<? extends Compressor> getCompressorType() { checkNativeCodeLoaded(); return SnappyCompressor.class; }
SnappyCompressor类部分方法详解&压缩流程
- compress
- needsInput
- reset
-
compress
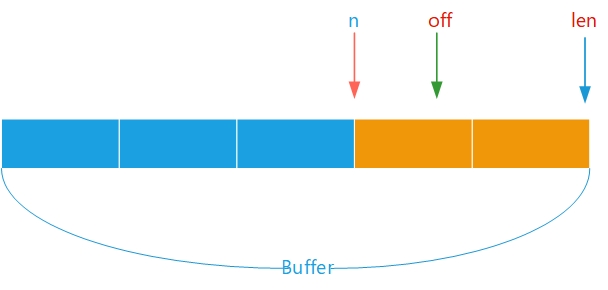
该方法是核心的压缩方法,压缩过程维护一个Buffer缓存区.首先检查Buffer缓冲区中是否有数据如果有从已有的数据开始压缩 同时
bytesWritten++,返回最终实际压缩的数据量.
@Override
public int compress(byte[] b, int off, int len)
throws IOException {
if (b == null) {
throw new NullPointerException();
}
if (off < 0 || len < 0 || off > b.length - len) {
throw new ArrayIndexOutOfBoundsException();
}
// 检查是否有数据
int n = compressedDirectBuf.remaining();
if (n > 0) {
n = Math.min(n, len);
((ByteBuffer) compressedDirectBuf).get(b, off, n);
bytesWritten += n;
return n;
}
SnappyDecompressor类部分方法详解&解压流程
- setInputFromSavedData
- decompress
- decompressDirect
- setInputFromSavedData 如果当前的写入的数据超出了直接缓冲区,调用rewind重新初始化snappy的直接缓冲区
void setInputFromSavedData() {
compressedDirectBufLen = Math.min(userBufLen, directBufferSize);
// Reinitialize snappy's input direct buffer
compressedDirectBuf.rewind();
((ByteBuffer) compressedDirectBuf).put(userBuf, userBufOff,
compressedDirectBufLen);
userBufOff += compressedDirectBufLen;
userBufLen -= compressedDirectBufLen;
}
-
decompress
decompress方法和compress逻辑脚本类似,不再解释.
-
decompressDirect
为native方法,直接调用snappy的C++库.
总结
以上为笔者总结压缩和解压部分源代码,感兴趣的读者可以继续深入学习,希望本文对读者起到一定的帮助.
参考
- https://github.com/apache/hadoop/blob/trunk/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/io/compress/
- http://hadoop.apache.org/




