
前言
相信绝大多数的使用过HDFS的同学,都听说过Block(块),本文浅析以下Block结构.
Block作为HDFS的数据存储的一个原语.其block ID唯一标识了一个Block,每个Block都会有一个对应的时间戳.这个时间戳会被HDFS的NameNode持久化.
Block结构
每个Block会涉及到两类文件 Block文件和Block元数据文件.
public static final String BLOCK_FILE_PREFIX = "blk_";
public static final String METADATA_EXTENSION = ".meta";
从HDFS实际存储数据我们可以看到以下结构

获取每个Block块名字,为blk_1,blk_2,blk_3 …
public String getBlockName() {
return BLOCK_FILE_PREFIX + blockId;
}
Block真实数据和metaFile 正则匹配,如果是block真实数据文件格式为blk_数字,如果为meteFile格式为blk_数字_数字.meta
public static final Pattern blockFilePattern = Pattern.compile(BLOCK_FILE_PREFIX + "(-??\\d++)$");
public static final Pattern metaFilePattern = Pattern.compile(BLOCK_FILE_PREFIX +
"(-??\\d++)_(\\d++)\\" + METADATA_EXTENSION + "$");
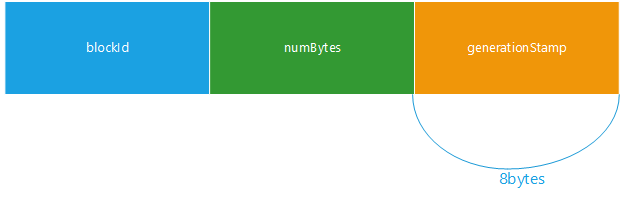
每个Block文件中会存储着三类元数据blockId,numBytes,generationStamp.
public void set(long blkid, long len, long genStamp) {
this.blockId = blkid;
this.numBytes = len;
this.generationStamp = genStamp;
}
通过blockId 比较两个block是否相等
public int compareTo(@Nonnull Block b) {
return Long.compare(blockId, b.blockId);
}
根据meta文件来创建对应的block数据文件,比如meta文件blk_1073741897_1073.meta通过该meta文件创建的block文件为blk_1073741897
public static File metaToBlockFile(File metaFile) {
return new File(metaFile.getParent(), metaFile.getName().substring(0, metaFile.getName().lastIndexOf('_')));
}
总结
以上为笔者总结仅仅是Block的源代码后续结合BlockInfo BlockMap分析,感兴趣的读者可以继续深入学习,希望本文对读者起到一定的帮助.
参考
- https://github.com/apache/hadoop
- http://hadoop.apache.org/




