
前言
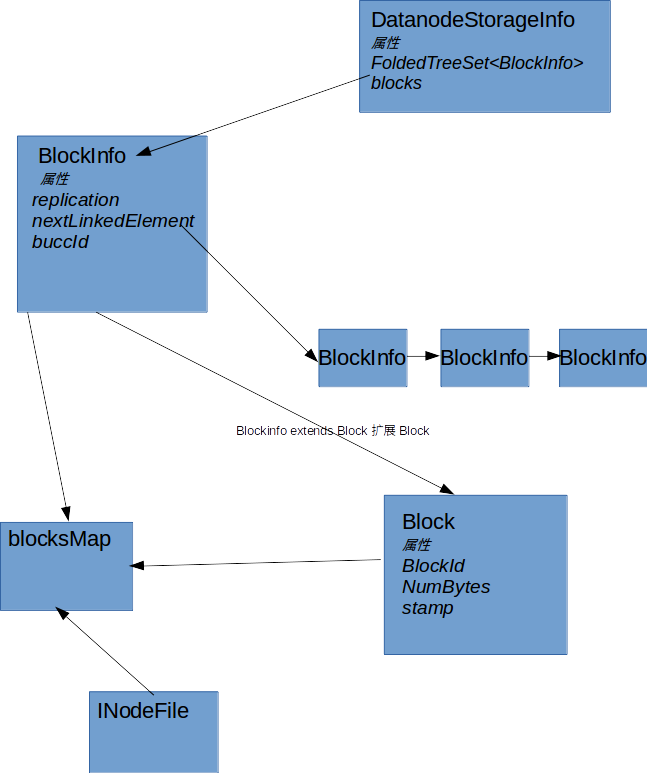
BlockInfo&BlockMap&DataNodeStorageInfo维护了数据块元数据关系.也就是我们通常所说的HDFS的元数据. 这些数据都存放在内存中,因此对于优化这些类的数据结构,一定程度上可以提高元数据存储内存的开销.下文我们 看一看源码中这些类的数据流和结构.
BlockInfo
BlockInfo该类为抽象类继承自Block是Block的扩展,其中扩展了块的副本,块和INodeFile的关系,处于UC态的
块属性以及块集合中块的ID,Block指向下一个Block的链表结构以及和DataNodeStorageInfo关联关系.该类的实现
类有BlockInfoContiguous,BlockInfoStriped即纠删码以及普通的副本存储.
- BlockInfo构造方法
public BlockInfo(Block blk, short size) {
super(blk);
//每个BlockInfo对应一个DatanodeStorageInfo数组
this.storages = new DatanodeStorageInfo[size];
//初始化的时候INODE 为无效
this.bcId = INVALID_INODE_ID;
//判断是否是纠删码决定其副本
this.replication = isStriped() ? 0 : size;
}
- 添加Storage
boolean addStorage(DatanodeStorageInfo storage, Block reportedBlock) {
int lastNode = ensureCapacity(1);
setStorageInfo(lastNode, storage);
return true;
}
void setStorageInfo(int index, DatanodeStorageInfo storage) {
this.storages[index] = storage;
}
- 转换块为UC状态
public void convertToBlockUnderConstruction(BlockUCState s,
DatanodeStorageInfo[] targets) {
if (isComplete()) {
uc = new BlockUnderConstructionFeature(this, s, targets,
this.getBlockType());
} else {
// 设置块为UC状态
uc.setBlockUCState(s);
//设置应该放置的位置
uc.setExpectedLocations(this, targets, this.getBlockType());
}
}
DatanodeStorageInfo
DatanodeStorageInfo官方解释一个DataNode有一个或者多个Storage,这个类代表一个Storage.其中比较重要的一个成员变量.FoldedTreeSet<BlockInfo> blocks
在Hadoop3.0之前该类使用的普通的TreeSet尚未经过优化,查找插入开销大.优化后的采用了红黑树的方式存储Storage中的BlockInfo的数据结构,红黑树在查找和插入速度
有了比较大的提升.
- 添加block
public AddBlockResult addBlock(BlockInfo b, Block reportedBlock) {
//检查是否block在同样的DN上不同的storage
AddBlockResult result = AddBlockResult.ADDED;
DatanodeStorageInfo otherStorage =
b.findStorageInfo(getDatanodeDescriptor());
if (otherStorage != null) {
if (otherStorage != this) {
// 这个block是在不同的storage上首先移除
otherStorage.removeBlock(b);
result = AddBlockResult.REPLACED;
} else {
//说明已经存在
return AddBlockResult.ALREADY_EXIST;
}
}
//添加当前block到BlockInfo
b.addStorage(this, reportedBlock);
blocks.add(b);
return result;
}
- 更新DatanodeStorage状态
void updateState(StorageReport r) {
//容量
capacity = r.getCapacity();
//已经使用的量
dfsUsed = r.getDfsUsed();
//非HDFS使用量
nonDfsUsed = r.getNonDfsUsed();
//剩余容量
remaining = r.getRemaining();
//BP池使用量
blockPoolUsed = r.getBlockPoolUsed();
}
BlockMap
BlockMap维护了一个Map,这个Map包括Block到他的元数据的映射,块的元数据包括了他当前所属的集合以及所属的DataNode.
- 构造方法中,new LightWeightGSet之前该类使用的是HashMap,切换为GSet不会执行任何hash冲突解决,并且数组也不会移动.
BlocksMap(int capacity) {
// Use 2% of total memory to size the GSet capacity
this.capacity = capacity;
this.blocks = new LightWeightGSet<Block, BlockInfo>(capacity) {
@Override
public Iterator<BlockInfo> iterator() {
SetIterator iterator = new SetIterator();
//防止并发修改异常
iterator.setTrackModification(false);
return iterator;
}
};
}
- 添加块映射关系
BlockInfo addBlockCollection(BlockInfo b, BlockCollection bc) {
//从GSet中获取b的BlockInfo
BlockInfo info = blocks.get(b);
//如果不相等
if (info != b) {
//把当前的BlockInfo赋值给info
info = b;
//把info添加到block中
blocks.put(info);
incrementBlockStat(info);
}
//关联INodeFile ID
info.setBlockCollectionId(bc.getId());
return info;
}
- 删除块和元数据映射管理
void removeBlock(BlockInfo block) {
//从GSet中移除
BlockInfo blockInfo = blocks.remove(block);
//如果根本就不存在直接退出函数
if (blockInfo == null) {
return;
}
decrementBlockStat(block);
//判断移除的块的是否为无效的块
assert blockInfo.getBlockCollectionId() == INodeId.INVALID_INODE_ID;
//判断块是否是纠删码如果是纠删码获取
// 1.纠删码获取DatanodeStorageInfo数组长度
// 2.非纠删码获取所在节点数
final int size = blockInfo.isStriped() ?
blockInfo.getCapacity() : blockInfo.numNodes();
//循环查找存在的所有的DataNode节点
for(int idx = size - 1; idx >= 0; idx--) {
DatanodeDescriptor dn = blockInfo.getDatanode(idx);
//根据dn移除所有的块
if (dn != null) {
removeBlock(dn, blockInfo); // remove from the list and wipe the location
}
}
}
整体结构梳理
总结
以上为笔者总结BlockInfo&BlockMap,感兴趣的读者可以继续深入理解,希望本文对读者起到一定的帮助.
参考
- https://github.com/apache/hadoop
- http://hadoop.apache.org/




