
前言
在某些情况下,例如DN滚动升级,最好将DN置于维护状态,在这种状态下NN停止向DN发送读写数据,同时不会去复制这些处于维护状态 的DN上的块.因为DN可能需要离线10分钟然后再次回来,比如切换为维护状态就是一个例子,不需要额外的开销去复制副本.让DN处于维护状态 应用的场景有DN批量更新,还有机架需要进行维护.
执行步骤
- 配置文件添加如下内容
<property>
<name>dfs.hosts.maintenance</name>
<value>/etc/hadoop/conf/maintenance</value>
</property>
- 在maintenance配置文件中添加对应的主机名
`cat /etc/hadoop/conf/maintenance`
{
"hostName": "datanode-100",
"port": 50010,
"adminState": "IN_MAINTENANCE",
"maintenanceExpireTimeInMS": 1492543534000
}
{
"hostName": "datanode-101",
"port": 50010,
"adminState": "IN_MAINTENANCE",
"maintenanceExpireTimeInMS": 1492543534000
}
{
"hostName": "datanode-102",
"port": 50010,
"adminState": "IN_MAINTENANCE",
"maintenanceExpireTimeInMS": 1492543534000
}
- 在NameNode执行命令
`hdfs dfsadmin -refreshNodes`
源码追踪
相关类涉及到FSNamesystem,DatanodeManager,DatanodeAdminManager,HeartbeatManager,DatanodeManager涉及大量的
DataNode相关操作,比如删除DataNode,获取存活的DataNode,注册到NameNode等等.DatanodeAdminManager涉及到下线节点,使得节点
进入维护状态,HeartbeatManager涉及心跳类,比如获取使用容量,获取Xceiver线程数等等.
类似于下线,存在两种状态
- Entering Maintenance
- In Maintenance
FSNamesystem
从执行的流程上,输入了执行命令,会进入FSNamesystem的如下方法
void refreshNodes() throws IOException {
String operationName = "refreshNodes";
checkOperation(OperationCategory.UNCHECKED);
//检查权限
checkSuperuserPrivilege(operationName);
//刷新节点根据给定的配置文件
getBlockManager().getDatanodeManager().refreshNodes(new HdfsConfiguration());
//记录审计日志
logAuditEvent(true, operationName, null);
}
DatanodeManager
接下来进入如下方法,首先刷新配置文件,然后获取写锁,然后刷新DataNode节点
public void refreshNodes(final Configuration conf) throws IOException {
//刷新配置文件
refreshHostsReader(conf);
namesystem.writeLock();
try {
//刷新DataNode节点
refreshDatanodes();
//有可能版本不一致,统计版本
countSoftwareVersions();
} finally {
namesystem.writeUnlock();
}
}
刷新配置文件
private void refreshHostsReader(Configuration conf) throws IOException {
if (conf == null) {
conf = new HdfsConfiguration();
this.hostConfigManager.setConf(conf);
}
this.hostConfigManager.refresh();
}
刷新DataNode节点方法
private void refreshDatanodes() {
final Map<String, DatanodeDescriptor> copy;
synchronized (this) {
copy = new HashMap<>(datanodeMap);
}
for (DatanodeDescriptor node : copy.values()) {
// 如果不在主机列表中设置为disable
if (!hostConfigManager.isIncluded(node)) {
node.setDisallowed(true);
} else {
//获取正在处于维护状态的过期时常
long maintenanceExpireTimeInMS =
hostConfigManager.getMaintenanceExpirationTimeInMS(node);
//如果没有过期,则开始进入维护状态
if (node.maintenanceNotExpired(maintenanceExpireTimeInMS)) {
//开始维护模式
datanodeAdminManager.startMaintenance(
node, maintenanceExpireTimeInMS);
} else if (hostConfigManager.isExcluded(node)) {
//如果在配置文件中添加了排除的节点则排除
datanodeAdminManager.startDecommission(node);
} else {
//以上都不是则立即停止维护状态和下线状态
datanodeAdminManager.stopMaintenance(node);
datanodeAdminManager.stopDecommission(node);
}
}
//设置升级域
node.setUpgradeDomain(hostConfigManager.getUpgradeDomain(node));
}
}
DatanodeAdminManager
开始维护
public void startMaintenance(DatanodeDescriptor node,
long maintenanceExpireTimeInMS) {
//如果处于维护状态依然要设定过期时间
node.setMaintenanceExpireTimeInMS(maintenanceExpireTimeInMS);
if (!node.isMaintenance()) {
//如果不在维护状态则立即启动维护
hbManager.startMaintenance(node);
//
if (node.isEnteringMaintenance()) {
for (DatanodeStorageInfo storage : node.getStorageInfos()) {
LOG.info("Starting maintenance of {} {} with {} blocks",
node, storage, storage.numBlocks());
}
node.getLeavingServiceStatus().setStartTime(monotonicNow());
}
//
monitor.startTrackingNode(node);
} else {
LOG.trace("startMaintenance: Node {} in {}, nothing to do.",
node, node.getAdminState());
}
}
定期检测线程
void activate(Configuration conf) {
final int intervalSecs = (int) conf.getTimeDuration(
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_INTERVAL_KEY,
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_INTERVAL_DEFAULT,
TimeUnit.SECONDS);
checkArgument(intervalSecs >= 0, "Cannot set a negative " +
"value for " + DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_INTERVAL_KEY);
int blocksPerInterval = conf.getInt(
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_BLOCKS_PER_INTERVAL_KEY,
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_BLOCKS_PER_INTERVAL_DEFAULT);
final String deprecatedKey =
"dfs.namenode.decommission.nodes.per.interval";
final String strNodes = conf.get(deprecatedKey);
if (strNodes != null) {
LOG.warn("Deprecated configuration key {} will be ignored.",
deprecatedKey);
LOG.warn("Please update your configuration to use {} instead.",
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_BLOCKS_PER_INTERVAL_KEY);
}
checkArgument(blocksPerInterval > 0,
"Must set a positive value for "
+ DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_BLOCKS_PER_INTERVAL_KEY);
final int maxConcurrentTrackedNodes = conf.getInt(
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_MAX_CONCURRENT_TRACKED_NODES,
DFSConfigKeys
.DFS_NAMENODE_DECOMMISSION_MAX_CONCURRENT_TRACKED_NODES_DEFAULT);
checkArgument(maxConcurrentTrackedNodes >= 0, "Cannot set a negative " +
"value for "
+ DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_MAX_CONCURRENT_TRACKED_NODES);
Class cls = null;
try {
cls = conf.getClass(
DFSConfigKeys.DFS_NAMENODE_DECOMMISSION_MONITOR_CLASS,
DatanodeAdminDefaultMonitor.class);
monitor =
(DatanodeAdminMonitorInterface)ReflectionUtils.newInstance(cls, conf);
monitor.setBlockManager(blockManager);
monitor.setNameSystem(namesystem);
monitor.setDatanodeAdminManager(this);
} catch (Exception e) {
throw new RuntimeException("Unable to create the Decommission monitor " +
"from "+cls, e);
}
executor.scheduleAtFixedRate(monitor, intervalSecs, intervalSecs,
TimeUnit.SECONDS);
}
HeartbeatManager
synchronized void startMaintenance(final DatanodeDescriptor node) {
//如果节点为死亡节点 直接进入维护状态
if (!node.isAlive()) {
LOG.info("Dead node {} is put in maintenance state immediately.", node);
node.setInMaintenance();
} else {
//降低容量配合
stats.subtract(node);
//如果已经下线完毕 则直接进入维护状态
if (node.isDecommissioned()) {
LOG.info("Decommissioned node " + node + " is put in maintenance state"
+ " immediately.");
node.setInMaintenance();
//如果副本数满足从进入维护状态到变成维护状态 直接设置为维护状态
} else if (blockManager.getMinReplicationToBeInMaintenance() == 0) {
LOG.info("MinReplicationToBeInMaintenance is set to zero. " + node +
" is put in maintenance state" + " immediately.");
node.setInMaintenance();
} else {
//开始进行维护状态
node.startMaintenance();
}
stats.add(node);
}
}
状态转化图
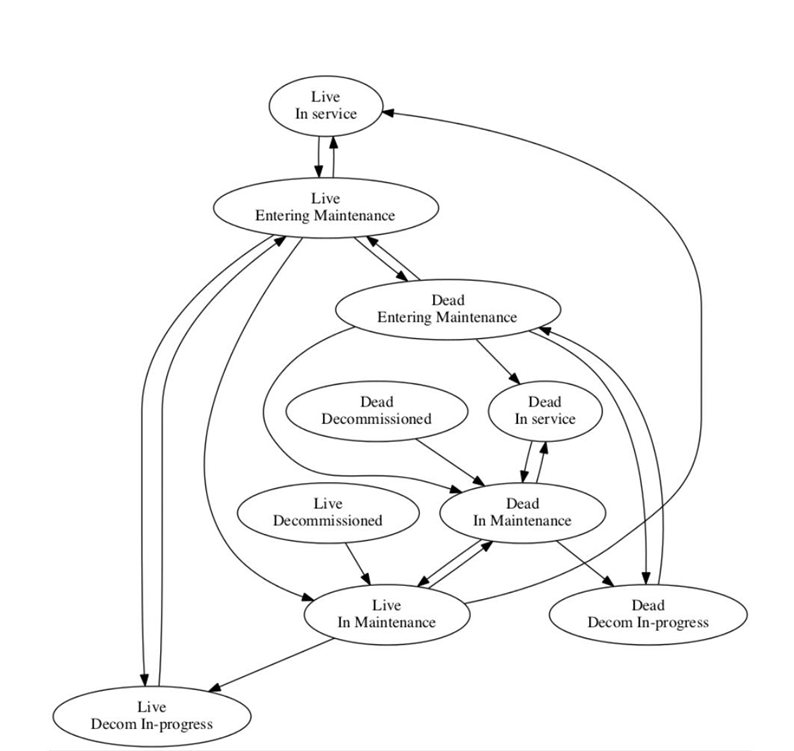
BlockManager应用维护模式
获取Block时,不要关心处于维护状态或者进入维护状态的或者是死亡的DataNode.
private LocatedBlock createLocatedBlock(LocatedBlockBuilder locatedBlocks,
final BlockInfo blk, final long pos) throws IOException {
// get block locations
NumberReplicas numReplicas = countNodes(blk);
final int numCorruptNodes = numReplicas.corruptReplicas();
final int numCorruptReplicas = corruptReplicas.numCorruptReplicas(blk);
....
if (numMachines > 0) {
final boolean noCorrupt = (numCorruptReplicas == 0);
for(DatanodeStorageInfo storage : blocksMap.getStorages(blk)) {
if (storage.getState() != State.FAILED) {
final DatanodeDescriptor d = storage.getDatanodeDescriptor();
// 不要关心处于维护状态或者进入维护状态的或者是死亡的DataNode.
if (d.isInMaintenance()
|| (d.isEnteringMaintenance() && !d.isAlive())) {
continue;
}
....
}
....
return blockIndices == null
? null == locatedBlocks ? newLocatedBlock(eb, machines, pos, isCorrupt)
: locatedBlocks.newLocatedBlock(eb, machines, pos, isCorrupt)
: newLocatedStripedBlock(eb, machines, blockIndices, pos, isCorrupt);
}
总结
以上为笔者Maintenance的总结,感兴趣的读者可以继续深入理解,希望本文对读者起到一定的帮助.
参考
- https://issues.apache.org/jira/browse/HDFS-7877
- http://hadoop.apache.org/
- https://issues.apache.org/jira/secure/attachment/12709388/Supportmaintenancestatefordatanodes-2.pdf
- https://blog.cloudera.com/hdfs-maintenance-state/




