
前言
HDFS磁盘写入数据的时候会存在磁盘写入速率不同导致磁盘使用比率差距可能会很大.但是我们可以手动移动 数据到其他的空间大的磁盘但是人为手动操作风险比较大.为了数据可以在命令行操作HDFS开发了磁盘平衡模块.该 新特性在Hadoop2.10&Hadoop3.0已经发布.本文笔者浅析磁盘均衡源码.
磁盘均衡使用
- 查询指定的集群
hdfs diskbalancer -query nodename.mycluster.com
- 生成执行计划
hdfs diskbalancer -uri hdfs://mycluster.com -plan node1.mycluster.com
- 执行执行计划
hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.json
- 取消执行计划
hdfs diskbalancer -cancel /system/diskbalancer/nodename.plan.json
- 按照执行ID和执行Node取消执行计划
hdfs diskbalancer -cancel <planID> -node <nodename>
磁盘平衡流程
- 发现需要平衡的节点
- 生成执行计划
- 执行执行计划
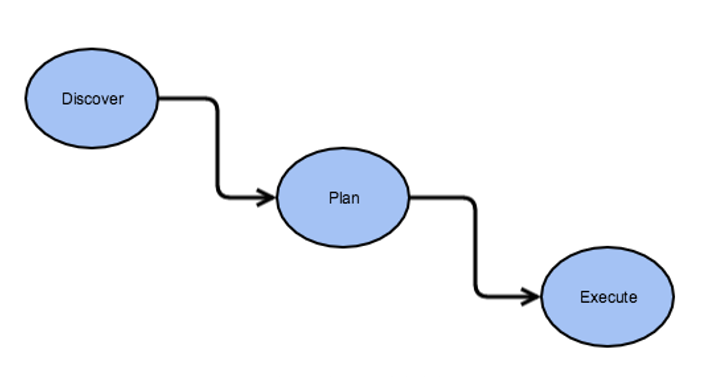
- 磁盘平衡器用于发现集群中的布局并且计算哪些节点需要磁盘均衡.
- 在执行计划阶段 磁盘平衡器为每一个数据节点计算一个执行计划,创建一组数据移动计划,由GreedyPlanner来执行
- 执行计划会执行SubmitPlan 调用MoveBlocks的接口移动数据,MoveBlocks是把数据从源磁盘移动到目标磁盘.
总体执行流程如下图:
磁盘均衡数据结构
总体的节点磁盘核心源代码结构如下图
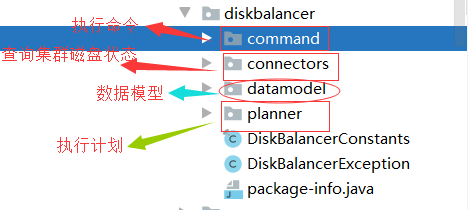
- command 执行命令
- connectors 磁盘发现器[discovery]
- datamodel 数据模型
- planner 执行过程和阶段
数据模型结构如下图:
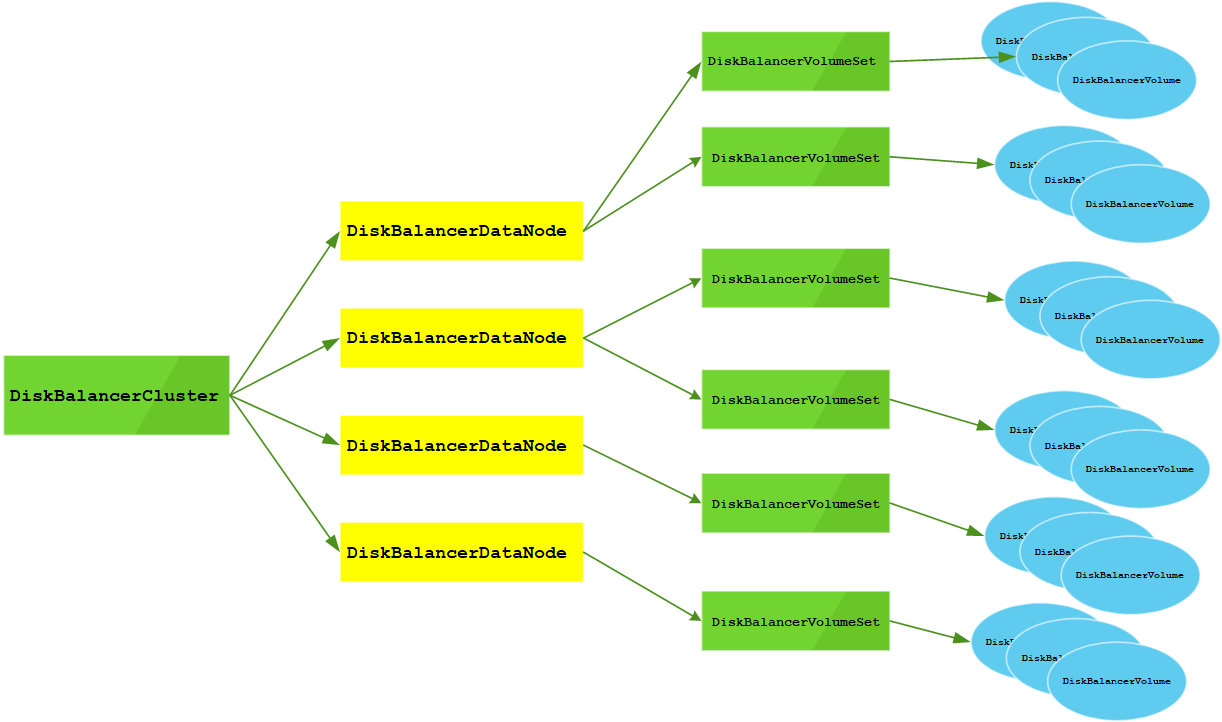
每个集群会用多个DataNode,每个DataNode会有多个磁盘逻辑卷集合,每个磁盘逻辑卷集合下对应多个磁盘.
执行命令类图结构如下图:
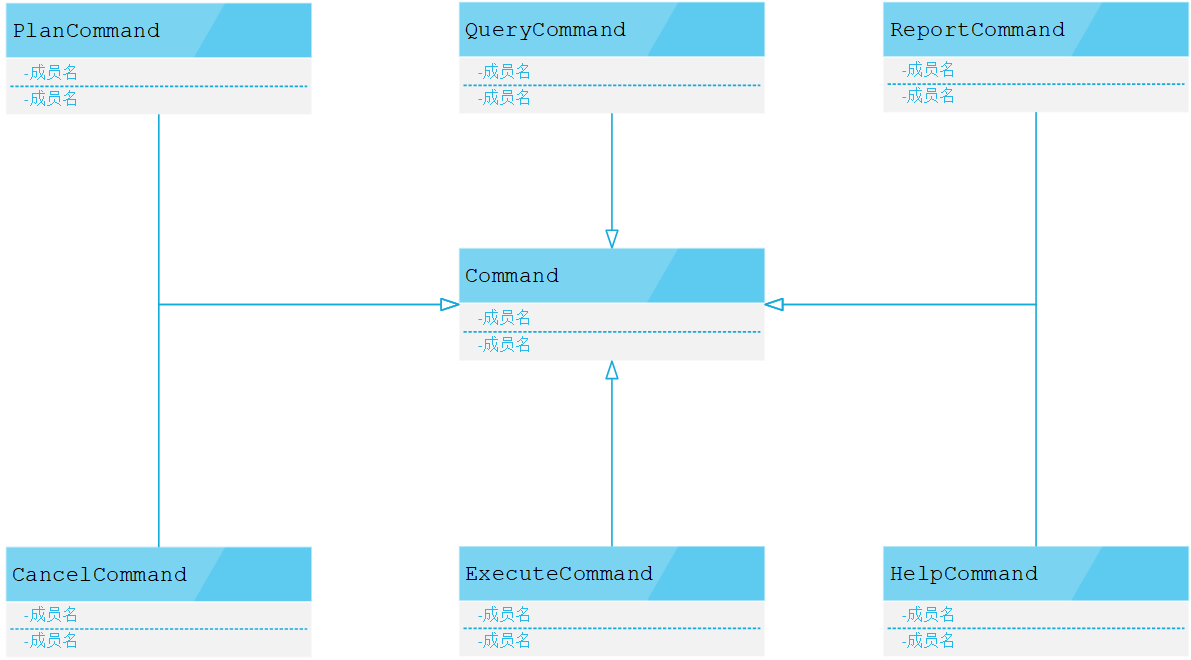
其中所有的Command继承自Command抽象类,PlanCommand为计划命令,QueryCommand查询命令,ExecuteCommand执行命令.
Discovery查询集群和JSON文件内容的类结构如下:
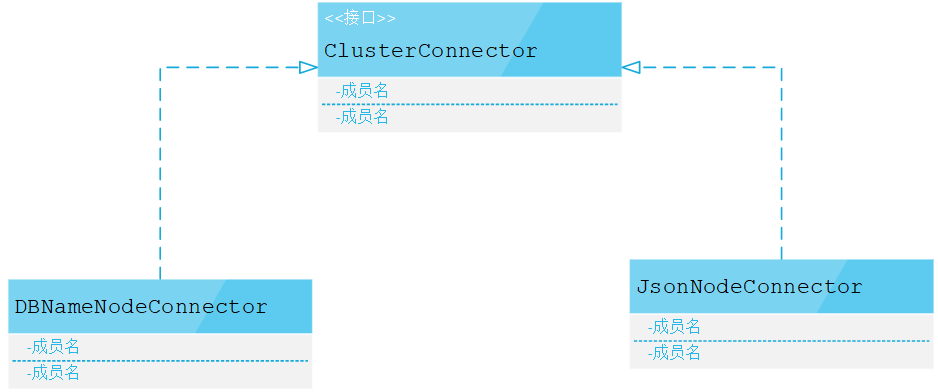
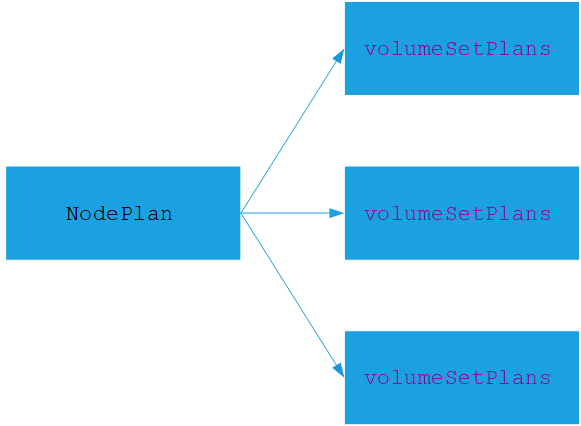
执行计划类结构如下:
执行平衡逻辑源代码跟踪
下面核心查看一下磁盘均衡源代码部分,打开ExecuteCommand类查看execute方法
@Override
public void execute(CommandLine cmd) throws Exception {
LOG.info("Executing \"execute plan\" command");
Preconditions.checkState(cmd.hasOption(DiskBalancerCLI.EXECUTE));
verifyCommandOptions(DiskBalancerCLI.EXECUTE, cmd);
//获取执行命令的JSON文件
String planFile = cmd.getOptionValue(DiskBalancerCLI.EXECUTE);
Preconditions.checkArgument(planFile != null && !planFile.isEmpty(),
"Invalid plan file specified.");
String planData = null;
//获取其中的数据
try (FSDataInputStream plan = open(planFile)) {
planData = IOUtils.toString(plan);
}
boolean skipDateCheck = false;
//判断是否强制执行
if(cmd.hasOption(DiskBalancerCLI.SKIPDATECHECK)) {
skipDateCheck = true;
LOG.warn("Skipping date check on this plan. This could mean we are " +
"executing an old plan and may not be the right plan for this " +
"data node.");
}
//提交执行
submitPlan(planFile, planData, skipDateCheck);
}
我们继续查看提交执行的源代码:
private void submitPlan(final String planFile, final String planData,
boolean skipDateCheck)
throws IOException {
Preconditions.checkNotNull(planData);
// 解析要执行的JSON数据为执行Node执行计划
NodePlan plan = NodePlan.parseJson(planData);
//获取DataNode地址
String dataNodeAddress = plan.getNodeName() + ":" + plan.getPort();
Preconditions.checkNotNull(dataNodeAddress);
//获取DataNode客户端协议
ClientDatanodeProtocol dataNode = getDataNodeProxy(dataNodeAddress);
//
String planHash = DigestUtils.shaHex(planData);
try {
//真正提交磁盘平衡计划
dataNode.submitDiskBalancerPlan(planHash, DiskBalancerCLI.PLAN_VERSION,
planFile, planData, skipDateCheck);
} catch (DiskBalancerException ex) {
LOG.error("Submitting plan on {} failed. Result: {}, Message: {}",
plan.getNodeName(), ex.getResult().toString(), ex.getMessage());
throw ex;
}
}
进入DataNode类查看如下真正提交磁盘执行计划
public void submitDiskBalancerPlan(String planID, long planVersion,
String planFile, String planData, boolean skipDateCheck)
throws IOException {
checkSuperuserPrivilege();
if (getStartupOption(getConf()) != StartupOption.REGULAR) {
throw new DiskBalancerException(
"Datanode is in special state, e.g. Upgrade/Rollback etc."
+ " Disk balancing not permitted.",
DiskBalancerException.Result.DATANODE_STATUS_NOT_REGULAR);
}
//提交任务
getDiskBalancer().submitPlan(planID, planVersion, planFile, planData,
skipDateCheck);
}
进入DiskBalancer类
public void submitPlan(String planId, long planVersion, String planFileName,
String planData, boolean force)
throws DiskBalancerException {
lock.lock();
try {
//检查是否已经开启平衡
checkDiskBalancerEnabled();
if ((this.future != null) && (!this.future.isDone())) {
LOG.error("Disk Balancer - Executing another plan, submitPlan failed.");
throw new DiskBalancerException("Executing another plan",
DiskBalancerException.Result.PLAN_ALREADY_IN_PROGRESS);
}
NodePlan nodePlan = verifyPlan(planId, planVersion, planData, force);
//创建工作计划
//实际上放到把NodePlan计划放到了ConcurrentHashMap<VolumePair, DiskBalancerWorkItem> workMap
createWorkPlan(nodePlan);
this.planID = planId;
this.planFile = planFileName;
this.currentResult = Result.PLAN_UNDER_PROGRESS;
//执行计划
executePlan();
} finally {
lock.unlock();
}
}
启动线程,开始执行线程调度
private void executePlan() {
Preconditions.checkState(lock.isHeldByCurrentThread());
this.blockMover.setRunnable();
if (this.scheduler.isShutdown()) {
this.scheduler = Executors.newSingleThreadExecutor();
}
this.future = scheduler.submit(new Runnable() {
@Override
public void run() {
Thread.currentThread().setName("DiskBalancerThread");
LOG.info("Executing Disk balancer plan. Plan File: {}, Plan ID: {}",
planFile, planID);
//根据给定的计划文件和计划ID
for (Map.Entry<VolumePair, DiskBalancerWorkItem> entry :
workMap.entrySet()) {
blockMover.setRunnable();
//移动数据块
blockMover.copyBlocks(entry.getKey(), entry.getValue());
}
}
});
}
总结
以上为笔者对DiskBalancer的概述,希望本文对读者起到一定的帮助.由于Hadoop更新了
common-codec依赖为1.11版本,使得shaHex方法变成了过时方法,笔者 给社区提交一个
issue HDFS-15347.切换为sha1Hex.
参考
- https://issues.apache.org/jira/browse/HDFS-1312
- https://issues.apache.org/jira/secure/attachment/12810720/Architecture_and_test_update.pdf
- https://blog.csdn.net/androidlushangderen/article/details/51776103




