目前我们使用Hive的大多数时候采用的HiveCli模式,但是HiveCli模式有一些短板,比如Ranger无法控制权限,所执行的相关脚本无法
被Atlas捕获记录数据血缘关系,在交互方面HiveCli交互体验效果不是太好等等,Hive社区逐渐地抛弃HiveCli.
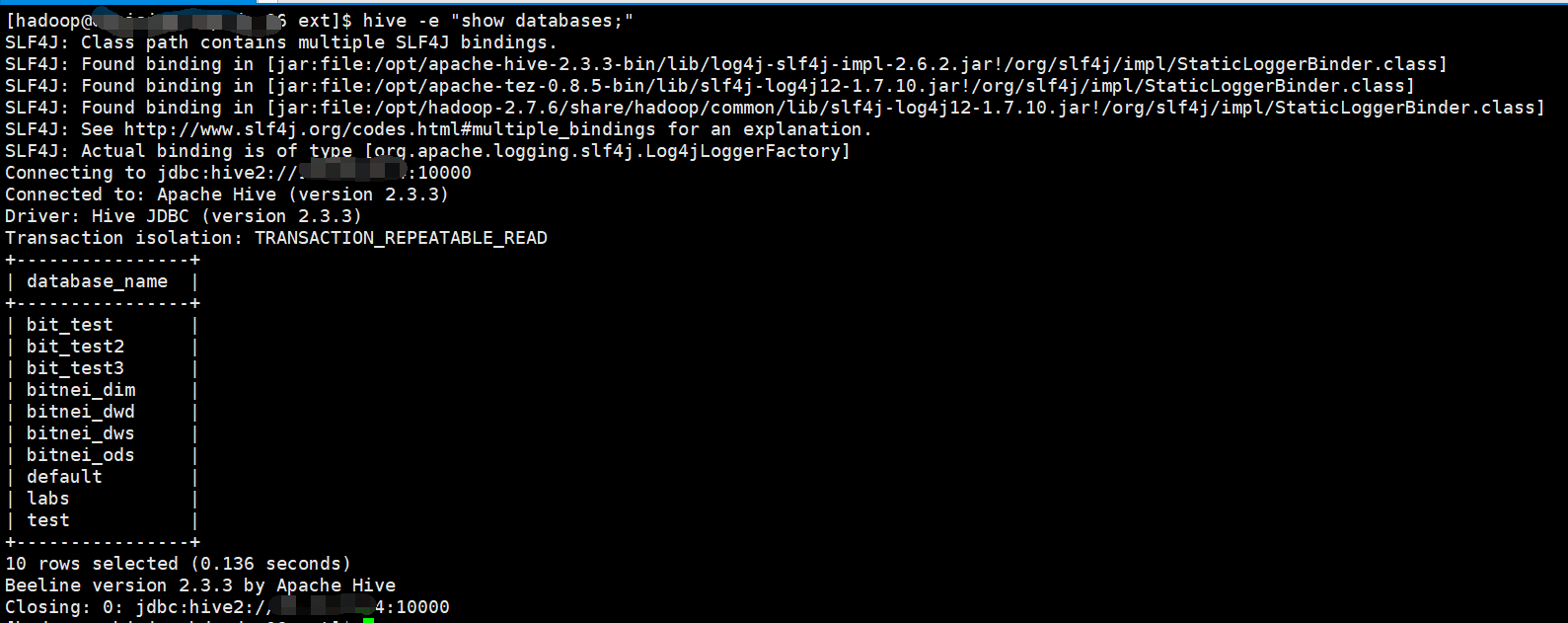
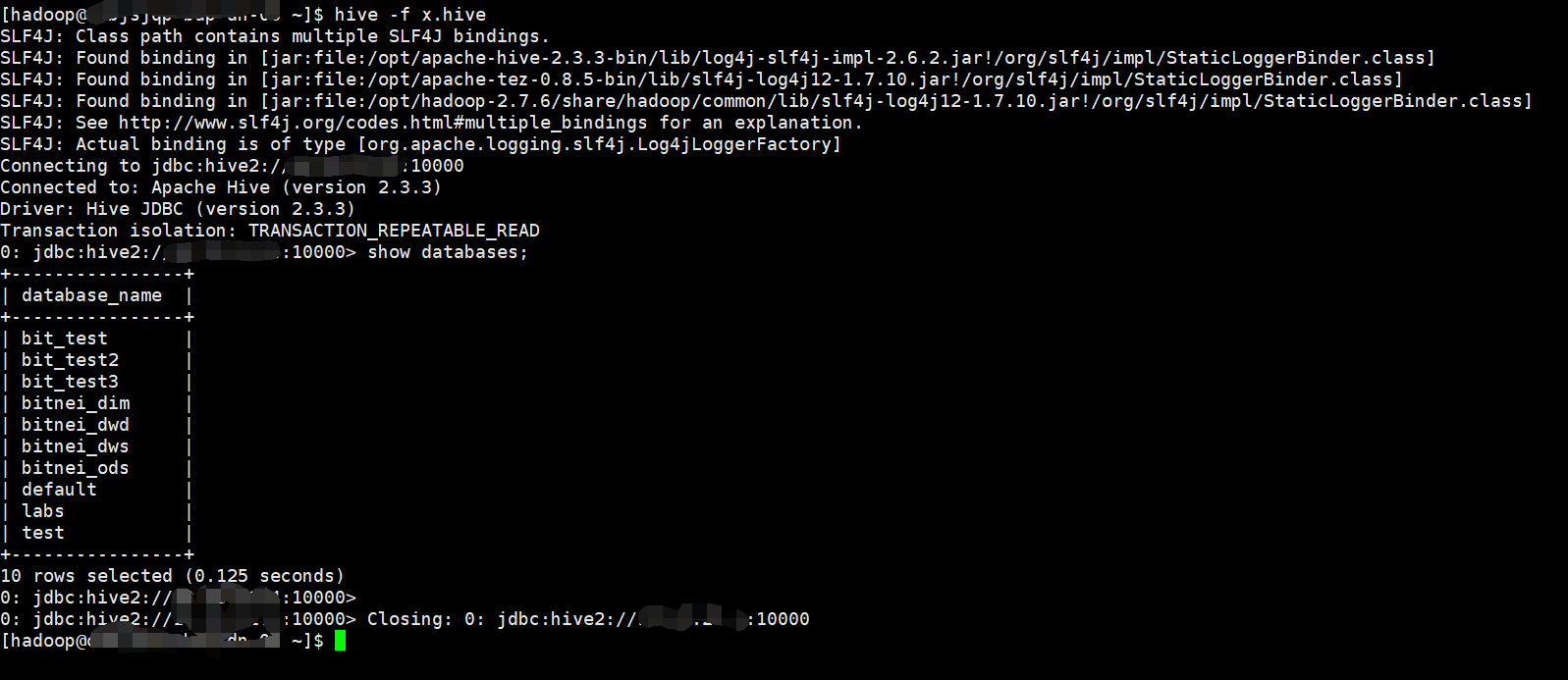
生产环境通常使用诸如Zeus,Hera,Easyscheduler调度中心执行HQL,默认直接执行`hive -e "show databases;"`或者执行文件
`hive -f show.hive`,由于生产环境已经使用了将近两年的`hive`命令.目前我们打算切换到`beeline`,但是如果一个一个去修改调度中
中心的脚本文件几乎不太可能.最终我们采用二次修改开发`hive`本身命令的内容,达到了无缝切换`beeline`方式.
if [ $# -eq 0 ]
then
echo "you must input -f to execute hive file or -e to query hive sql"
exit -1;
fi
if [ "$SERVICE" = "" ] ; then
if [ "$HELP" = "_help" ] ; then
SERVICE="help"
else
SERVICE="beeline"
fi
fi
THISSERVICE=beeline
export SERVICE_LIST="${SERVICE_LIST}${THISSERVICE} "
beeline () {
CLASS=org.apache.hive.beeline.BeeLine;
# include only the beeline client jar and its dependencies
beelineJarPath=`ls ${HIVE_LIB}/hive-beeline-*.jar`
superCsvJarPath=`ls ${HIVE_LIB}/super-csv-*.jar`
jlineJarPath=`ls ${HIVE_LIB}/jline-*.jar`
hadoopClasspath=""
if [[ -n "${HADOOP_CLASSPATH}" ]]
then
hadoopClasspath="${HADOOP_CLASSPATH}:"
fi
export HADOOP_CLASSPATH="${hadoopClasspath}${HIVE_CONF_DIR}:${beelineJarPath}:${superCsvJarPath}:${jlineJarPath}"
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Dlog4j.configurationFile=beeline-log4j2.properties "
#exec $HADOOP jar ${beelineJarPath} $CLASS $HIVE_OPTS "$@"
exec $HADOOP jar ${beelineJarPath} $CLASS $HIVE_OPTS -u "jdbc:hive2://ip:10000" -n${USER} -p123456789 "$@"
}
beeline_help () {
beeline "--help"
}
以上是笔者总结的hivecli到hiveserver2无缝切换,希望对读者起到一定帮助作用.