
前言
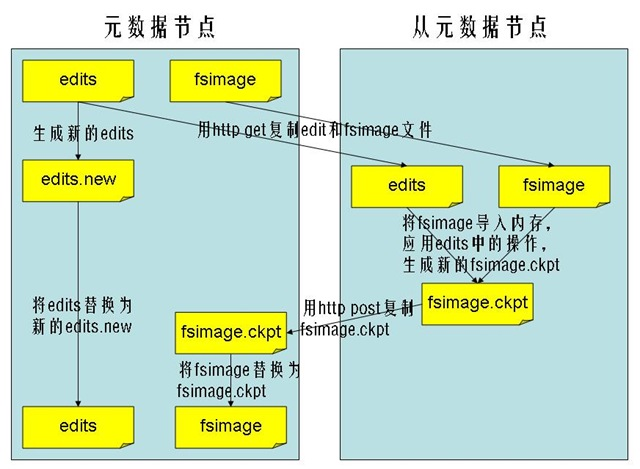
在HDFS非HA环境中,BackupNameNode[BNN]负责定期下载ActiveNameNode[ANN]fsedits和fsimage到本地将其合并,然后再重新上传回ANN.
在HDFS高可用环境中,StandbyNameNode[SNN]定期下载ANN fsedits和fsimage到本地然后将其合并,最后重新上传回ANN.
Checkpinter扮演的这个角色,他会定期检查和合并HDFS元数据.checkpointer为一个线程类,用户可以指定Edit文件大小,以及合并的时间.
checkpointer会根据这两个条件触发从namenode上下载fsimage和edit文件然后合并然后上传回到ANN.本文我们深入源码梳理梳理非HA的checkpointer大致合并流程.
合并概览
-
BNN下载ANN的editlog&fsimage
-
BNN本地合并
-
BNN再次上传回到ANN
贴一张网上的图片
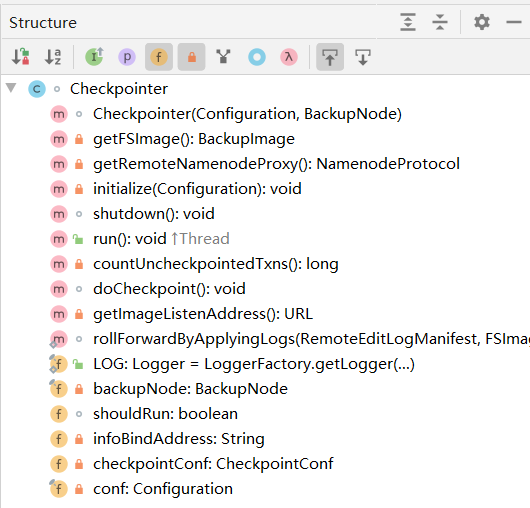
Checkpointer类结构
checkpointer类是一个线程类,我们可以从run()方法入手,类的大体结构如下图,这边提及重要的方法.
- run() 根据触发条件触发checkpointer
- countUncheckpointedTxns() 统计未进行checkpoint的txns
- doCheckpoint() 核心方法进行checkpointer
- rollForwardByApplyingLogs() 根据日志进行滚动合并
执行流程
对于线程类,首先看run() 方法,然后寻找run() 方法中核心的下一个调用的方法doCheckpoint()
. run()方法执行的判断的流程如下图:
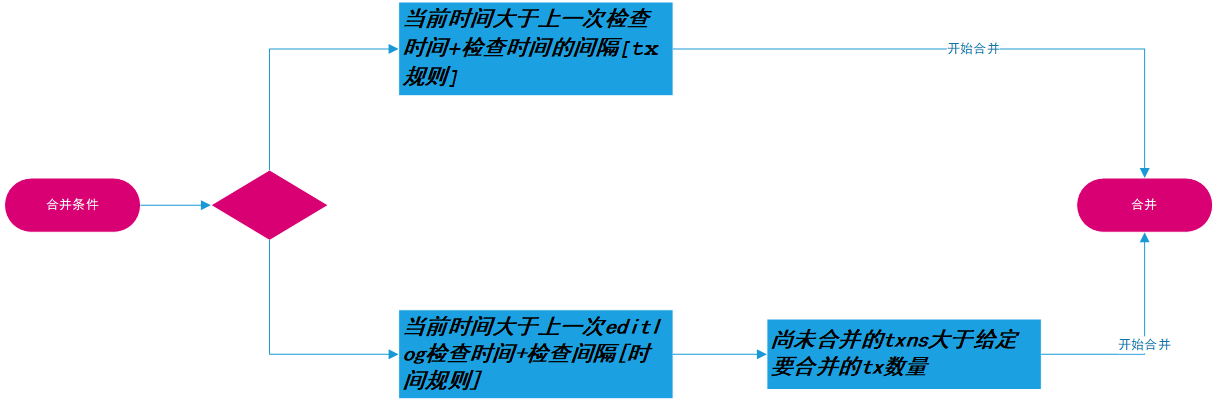
- 当前时间大于上一次检查时间+检查时间间隔[tx次数规则]
- 当前时间大于上一次editlog检查时间+检查间隔[时间规则]
根据如上规则,判断是否进行checkpointer,源代码如下
@Override
public void run() {
//多久检查一次
long periodMSec = checkpointConf.getCheckPeriod() * 1000;
// 经过多少个Tx阶段检查一次(旧版本是按照文件的大小检查)
long checkpointPeriodMSec = checkpointConf.getPeriod() * 1000;
long lastCheckpointTime = 0;
long lastEditLogCheckTime =0;
//不应该在启动的时候就检查
if (!backupNode.shouldCheckpointAtStartup()) {
lastCheckpointTime = monotonicNow();
}
//死循环让他一直检测
while(shouldRun) {
try {
long now = monotonicNow();
boolean shouldCheckpoint = false;
//当前时间大于上一次检查时间+检查时间的间隔[tx规则] 则置为 true 开始checkpoint
if(now >= lastCheckpointTime + checkpointPeriodMSec) {
shouldCheckpoint = true;
//当前时间大于上一次editlog检查时间+检查间隔[时间规则] 则置为true 开始checkpoint
} else if(now >= lastEditLogCheckTime + periodMSec) {
//统计未checkpint 的tx数量
long txns = countUncheckpointedTxns();
//把现在时间置为上一次editlog检查时间
lastEditLogCheckTime = now;
//如果未checkpoint tx数量大于了给定的tx数量
if(txns >= checkpointConf.getTxnCount())
//开始checkpoint
shouldCheckpoint = true;
}
if(shouldCheckpoint) {
//开始checkpoint
doCheckpoint();
lastCheckpointTime = now;
lastEditLogCheckTime = now;
}
} catch(IOException e) {
LOG.error("Exception in doCheckpoint: ", e);
} catch(Throwable e) {
LOG.error("Throwable Exception in doCheckpoint: ", e);
shutdown();
break;
}
try {
//线程停顿时长 = 检查时间间隔 TXID最大公约数
Thread.sleep(LongMath.gcd(periodMSec, checkpointPeriodMSec));
} catch(InterruptedException ie) {
// do nothing
}
}
}
接下来是doCheckpoint()方法,执行的大体流程如下图

源代码解释如下:
void doCheckpoint() throws IOException {
//获取Backup上fsimage
BackupImage bnImage = getFSImage();
//通过image获取storage
NNStorage bnStorage = bnImage.getStorage();
long startTime = monotonicNow();
// 停止本地edits文件合并 fsimage
bnImage.freezeNamespaceAtNextRoll();
//获取cmd命令
NamenodeCommand cmd =
getRemoteNamenodeProxy().startCheckpoint(backupNode.getRegistration());
CheckpointCommand cpCmd = null;
switch(cmd.getAction()) {
//关闭
case NamenodeProtocol.ACT_SHUTDOWN:
shutdown();
throw new IOException("Name-node " + backupNode.nnRpcAddress
+ " requested shutdown.");
//合并
case NamenodeProtocol.ACT_CHECKPOINT:
cpCmd = (CheckpointCommand)cmd;
break;
default:
throw new IOException("Unsupported NamenodeCommand: "+cmd.getAction());
}
//冻结bn的namespace,直到bn接受到下一次的滚动请求
bnImage.waitUntilNamespaceFrozen();
//获取唯一签名 其中包括了checkpoint的唯一性
CheckpointSignature sig = cpCmd.getSignature();
// Make sure we're talking to the same NN!
//校验bnImage
// 1. 是否是同一个集群
// 2. 是否是同一个版本
sig.validateStorageInfo(bnImage);
//获取最后一次的TxId
long lastApplied = bnImage.getLastAppliedTxId();
//根据fsimage中的txid获取最后一次的editlog清单
RemoteEditLogManifest manifest =
getRemoteNamenodeProxy().getEditLogManifest(bnImage.getLastAppliedTxId() + 1);
//是否需要重新加载FSimage
boolean needReloadImage = false;
//如果元数据列表不为空
if (!manifest.getLogs().isEmpty()) {
//获取第一个logs文件
RemoteEditLog firstRemoteLog = manifest.getLogs().get(0);
if (firstRemoteLog.getStartTxId() > lastApplied + 1) {
//从active namenode 下载fsimage
MD5Hash downloadedHash = TransferFsImage.downloadImageToStorage(
backupNode.nnHttpAddress, sig.mostRecentCheckpointTxId, bnStorage,
true, false);
//保存MD5&重命名[fsimage.ckpt] 镜像到 BackupNamenode
bnImage.saveDigestAndRenameCheckpointImage(NameNodeFile.IMAGE,
sig.mostRecentCheckpointTxId, downloadedHash);
//保存上一次的checkpoint 的txid
lastApplied = sig.mostRecentCheckpointTxId;
//需要加载镜像标记为true
needReloadImage = true;
}
//如果开始的txid大于上一次的txid+1说明根本没有editlog文件
if (firstRemoteLog.getStartTxId() > lastApplied + 1) {
throw new IOException("No logs to roll forward from " + lastApplied);
}
for (RemoteEditLog log : manifest.getLogs()) {
//从ANN下载edits文件
TransferFsImage.downloadEditsToStorage(
backupNode.nnHttpAddress, log, bnStorage);
}
if(needReloadImage) {
//重新加载fsimage文件
File file = bnStorage.findImageFile(NameNodeFile.IMAGE,
sig.mostRecentCheckpointTxId);
bnImage.reloadFromImageFile(file, backupNode.getNamesystem());
}
//滚动应用editlog
rollForwardByApplyingLogs(manifest, bnImage, backupNode.getNamesystem());
}
//获取fsimage最后一次合并后的txid
long txid = bnImage.getLastAppliedTxId();
//获取namespace写锁
backupNode.namesystem.writeLock();
try {
backupNode.namesystem.setImageLoaded();
//获取块的总个数
if(backupNode.namesystem.getBlocksTotal() > 0) {
//获取完整的块 去除掉UC[正在构建的]块
long completeBlocksTotal =
backupNode.namesystem.getCompleteBlocksTotal();
//设置完整块的个数
backupNode.namesystem.getBlockManager().setBlockTotal(
completeBlocksTotal);
}
//保存合并后的fsimage
bnImage.saveFSImageInAllDirs(backupNode.getNamesystem(), txid);
if (!backupNode.namenode.isRollingUpgrade()) {
//更新存储版本
bnImage.updateStorageVersion();
}
} finally {
backupNode.namesystem.writeUnlock("doCheckpoint");
}
if(cpCmd.needToReturnImage()) {
//重新上传到
TransferFsImage.uploadImageFromStorage(backupNode.nnHttpAddress, conf,
bnStorage, NameNodeFile.IMAGE, txid);
}
//结束check pointer
getRemoteNamenodeProxy().endCheckpoint(backupNode.getRegistration(), sig);
if (backupNode.getRole() == NamenodeRole.BACKUP) {
//追赶最新的editlog文件
bnImage.convergeJournalSpool();
}
backupNode.setRegistration(); // keep registration up to date
long imageSize = bnImage.getStorage().getFsImageName(txid).length();
LOG.info("Checkpoint completed in "
+ (monotonicNow() - startTime)/1000 + " seconds."
+ " New Image Size: " + imageSize);
}
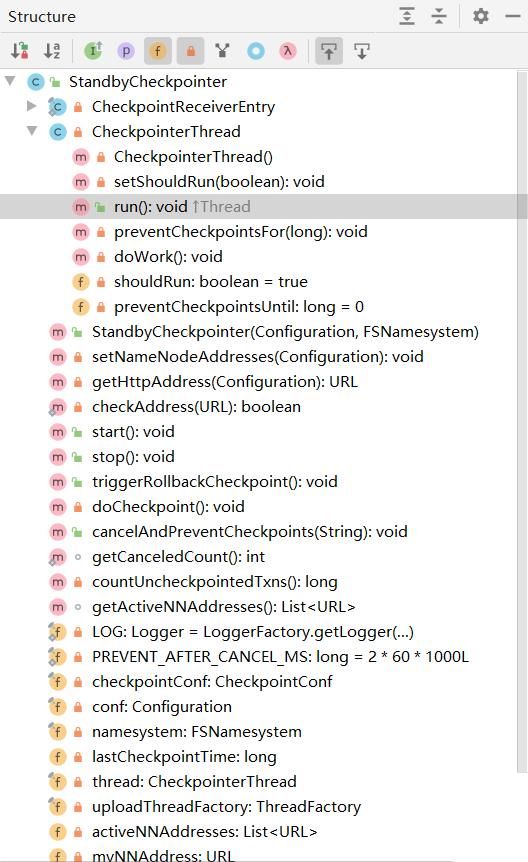
StandbyCheckPointer类结构
在高可用集群中也会涉及到checkpointer线程合并edits文件和fsimage文件线程,该类的结构如下,这个类相对来说要复杂一下,一下截图笔者罗列了他的方法,感兴趣的读者可以现在源代码学习.
参考
- https://hadoop.apache.org/




